广告

从去年初与李世石的围棋人机大战,到年底化身神秘棋手横扫中日韩三国顶尖高手,AlphaGo把围棋界搅了个人仰马翻,也把全球的目光都再次聚焦到本来就已经高热的人工智能上。AlphaGo是一个很复杂的系统吗?今天,有个技术大牛想教教你,用28天造出一个属于你的AlphaGo。
一、围棋AI基础
大家都知道AlphaGo v13的三大组件是:
MCTS(蒙特卡洛树搜索)
CNN(卷积神经网络,包括:策略网络 policy network、快速走子网络 playout network、价值网络 value network)
RL (强化学习)现有的围棋AI也都是这个思路了,我们也会按这个思路讲。在此先看看围棋和博弈AI的一些基本常识。
1、首先是围棋规则。
围棋博大精深,但基本规则很简洁。推荐这个在线教程:
第一天 围棋的介绍 - 十天即可掌握!『PANDANET围棋入门』注意,正常来说,黑棋的第 1 手要下到你的右上角,比如说右上角的"星位"或者"小目"。虽然棋盘是对称的,下其它三个角也可以,但这是对弈的一种礼貌,这样下对方就知道你是懂规矩的(当然,也可以第 1 手下在边上,或者中腹,但目前人类一般认为是亏的)。
如果等不及,看完教程的"第一天"内容,其实就可以立刻玩一下了。下图是纯神经网络走棋,你持黑,电脑持白(因为黑棋先走,有优势,所以最后要倒贴几目给白棋,叫做贴目),大家可以点击打开:
Play Go Against a DCNN这个网页第一次打开会比较慢,因为要加载一个 50M 的神经网络数据。
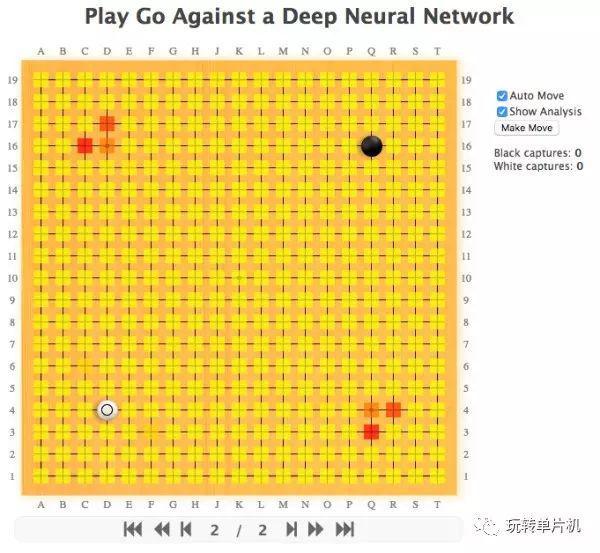
图中的颜色可以点击 "Show Analysis" 打开,是神经网络的最终输出。越红的地方,代表神经网络认为越可能成为下一手。你也可以把 "Auto Move" 关掉,自己和自己下。
试试先按电脑的建议,走在红的地方,培养一下"感觉"吧!
如果有多个红点,可以任选一个。当然,不可迷信,它的红点时常是错的,也时常不全面!
这个电脑不会计算,完全没有搜索,全部都是靠神经网络的“感觉”,用围棋的话说,可以说是按照"定式"和"常型"等等,所以死活弱(就是你可能会有机会把它的棋吃掉!),很适合新人找感觉。
2、围棋规则实际有很多细节,而且并没有世界统一的规则。
现有的规则有中国、韩国、日本、应式等等,在大多数情况下不影响胜负的判断结果,但还是有微妙区别,比如说中国是数子,有"粘劫收后",日韩是数目,终局有死活的判断问题。
较为简洁,适合电脑描述的可能是 Tromp-Taylor 规则: Tromp-Taylor Rules 。不妨做几个调整:
a. 再简化一点,去掉"全局禁同形再现",改成"罕见循环局面由裁判决定"(毕竟三劫以上循环的可能性很小),这样程序就不一定要存一个每个局面的hash表。
b. 禁止自杀,这样更接近其它规则。
c. 虽然目前看最佳贴目可能更接近 5.5,但还是按中国现有规则的 7.5 吧,方便大家统一。目前市面最强的程序是 银星17 和 Zen6,不过价钱也比较高(虽然都有X版)。而目前免费软件中最强的是 Leela,棋力也还不错,请点击:chess, audio and misc. software
而且 Leela 有 console 的接口,可以接上目前常用的围棋 GTP 协议。如果你有兴趣,现在还有一个电脑围棋的天梯,可以连进去与其它程序对战,看自己的排名: 19x19 All Time Ranks 。
3、关于蒙特卡洛树搜索
有一个常见的错误认识,在此先纠正。
在棋类博弈 AI 中,很多年前最早出现的是蒙特卡洛方法,就是到处随机走,然后看哪里的胜率最高。但这有一个问题,举个例子:
a. 如果走在 A,人有100种应对,其中99种,电脑会立刻赢,只有1种电脑会立刻输。
b. 如果走在 B,人有100种应对,但局势很复杂,大家都看不清,如果随机走下去,后续的胜率双方都是50%。那么如果计算蒙特卡洛的胜率,电脑会发现走在 A 的胜率是 99%,走在 B 的胜率是 50%。
可是,电脑的正解是应该走 B!因为如果走了 A,人如果够聪明,就一定会走电脑立刻输的变化。如果电脑执意要走 A,就只能称之为"骗着"了。
于是有的人会说蒙特卡洛方法有缺陷。但是,蒙特卡洛树搜索在理论上解决了这个问题。
怎么把人想象得尽量聪明?这就要靠博弈树。蒙特卡洛树搜索是博弈树和蒙特卡洛方法的结合,它不会犯 A 和 B 的问题,它很快就会发现 B 比 A 好。容易证明,如果给定足够的计算时间和足够的存储空间,蒙特卡洛树搜索可以收敛到完美的博弈树,成为围棋之神。
然而,实际的计算和存储资源是有限的,实际的 A (不妨称之为陷阱)也会更复杂。比如说:
c. 如果走在 A,经过博弈树的模拟,电脑几乎是怎么走都怎么赢;但是人更清楚后续的走法,人会走出完美的应对,在许多步后电脑一定会突然死亡。这时,电脑要走遍了博弈树的许多层,才能发现原来走到 A 会存在致命缺陷,掉入陷阱。这种情况下,蒙特卡洛树搜索就容易在 A 和 B 的问题上给出错误的答案。这有好多种表现,比如说"地平线效应",又像 AlphaGo 被击中的第 78 手。
围棋中是有很多陷阱局面的,比如说"大头鬼"。人工智能如何正确应对陷阱局面,或者避免进入陷阱局面?这就需要 策略网络(policy network)、价值网络(value network)、强化学习 的共同作用。在后续的文章将会逐步介绍,包括具体的训练方法。
二、安装 MXNet 搭建深度学习环境
介绍完围棋 AI 的基本常识,咱们开始搭建深度学习环境。
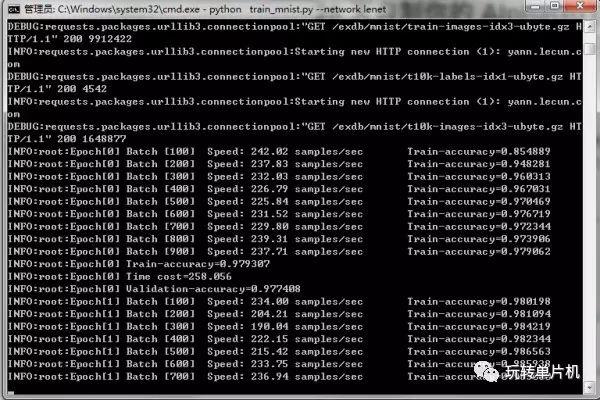
目前的环境很多,最多人用的是 Google 的 TensorFlow;不过 MXNet 感觉也蛮不错,比较省资源(当然,最好两个都装)。配图是 MXNet 的例子里面的 LeNet 训练 MNIST 数据集,这是很经典的模型,可以看到准确率在随着训练不断提高:
安装之前先看个好玩的:github.com/dmlc/mxnet.js 是在浏览器直接运行 MXNet 的效果。TensorFlow 也有类似的东西: transcranial/keras-js。也就说,我们训练好模型后,可以直接在网页里面可视化,这样就可以轻松跨平台。

1、Windows的安装
第一次装深度学习环境经常会遇到一些坑,这里看一个实际安装 MXNet 的过程。先看 Windows 的安装,比较简单和快速,因为不需要编译。
说句无关的,我个人是推荐 Windows 的,因为显卡还可以用于娱乐(这几年的新游戏的图像进步很大),有兴趣还可以玩个 VR 啥的。
1) 首先装了 VC2015,安装时语言记得选上 C++。
2)然后如果你有 nVidia 的 GPU,装一下 CUDA:CUDA 8.0 Downloads 。选本地安装版,建议用迅雷下比较快。如果没有 nVidia 显卡,买一块吧,显存尽量选大的,机器的电源也记得要跟上。实在没钱就二手 750Ti 2G 显存版吧,足够玩玩简单模型,因为 MXNet 省显存。当然,用 CPU 也可以跑,就是慢。
3)再下载 cuDNN,这个要注册一个帐号。注册一个吧: NVIDIA cuDNN 。解压备用。
4)下载 MXNet 的编译好的包:github.com/ 先下载 vc14 base package,然后下载更新包(例如 20170114_mxnet_x64_vc14_gpu.7z 注意 GPU 包就是同时支持 CPU 和 GPU)解压进去,然后把 cuDNN 也解压进去(见它的文档)。执行 setupenv.cmd 。
5)装个 Python 吧,推荐 Anaconda,选 Python 2.7 的版本: Download Anaconda Now! 。建议用迅雷下比较快。装完检验一下 python 命令可用。
6)进开始的 MXNet 目录的 python 子目录,执行 python setup.py install 。会发现提示要装一个 Microsoft Visual C++ Compiler for Python 2.7,去装了。
7)然后再执行 python setup.py install,可能会发现提示缺头文件,把他们从你的 VC2015 的 include 目录拷贝到 Microsoft Visual C++ Compiler for Python 2.7 的 include 目录即可。要根据提示拷贝好几个头文件。然后就可以成功编译了。
8)运行 python,然后 import mxnet 然后 (mxnet.nd.ones((2,2), mxnet.cpu())*100).asnumpy()然后 (mxnet.nd.ones((2,2), mxnet.gpu())*100).asnumpy() 如果全部成功,恭喜你,装好了。
9)再下载 dmlc/mxnet,在 example 目录 python train_mnist.py --network lenet 。会先下载测试数据,等下它,比较慢。看看是否成功训练。
10)再测试 VC++ 的环境。下载 MXNet.cpp (不需要执行里面的 setupenv.cmd),然后打开 windows 目录下面的 vs 下面的 MxnetTestApp,运行试试。再试试里面有句可以改成 Context ctx_dev(DeviceType::kGPU, 0); 会发现 GPU 确实比 CPU 快。
11)可以用 CPU-z 和 GPU-z 看你的 CPU 和 GPU 有没有偷懒,是否是在全心全意工作。2、Mac 的安装
下面看 Mac 的安装,我是 OSX 10.11。
这个安装麻烦一些,因为首先下面有些下载过程可能要 export ALL_PROXY="代理地址"(否则很慢)。另外 pip 也要换国内源,git 也要加代理,homebrew 也可以改国内源。
然后有时会遇到权限问题,请 chown 一下。有时可能也要 sudo。
1)装 XCode。最新 CUDA 已经兼容 XCode 8 了。
2)装 CUDA 和 cuDNN。
3)装 homebrew(百度搜索一下)。装 python,建议 brew install pyenv 然后用它装 anaconda2,防止破坏系统 python 版本:Mac OS X下安装pyenv 。注:如果发现 pyenv 下载文件奇慢无比,可以给 pyenv 加上 -v 看到找到下载路径,然后手工下载,然后打开 /usr/local/bin/python-build 然后在 download_tarball() 函数里面,直接把第一行改成 local package_url="http://127.0.0.1/Anaconda2-4.2.0-MacOSX-x86_64.sh" 然后你自己开一个 http 服务器即可。
4)装 MXNet: Installing MXNet on OS X (Mac) 按照 Standard installation 走。不要执行它的 Quick Installation 自动脚本,因为还会去重新装 homebrew,非常慢。
5)按它说的编译(非常慢)。在 config.mk 中加:
USE_BLAS = openblas
ADD_CFLAGS += -I/usr/local/opt/openblas/include
ADD_LDFLAGS += -L/usr/local/opt/openblas/lib
ADD_LDFLAGS += -L/usr/local/lib/graphviz/
USE_CUDA = 1
USE_CUDA_PATH = /usr/local/cuda
USE_CUDNN = 1
USE_NVRTC = 1另外可能要 ln -s /usr/local/cuda/lib /usr/local/cuda/lib64 。有问题就 make clean 一下再试试。
6)检查是否装好:
cd example/image-classification/
python train_mnist.py接下来,我们安装 TensorFlow,真正训练一下 AlphaGo v13 的 policy network,并且你还可以与它真正对弈,因为前几天已经有网友在做可以运行的 AlphaGo v13 的简化版:brilee/MuGo。所以这个过程真的已经很傻瓜化,毫不夸张地说,人人都可以拥有一只小狗了,只要你把棋谱喂给它,它就能学到棋谱的棋风。
TensorFlow 最近开始原生支持 Windows,安装很方便。
三、TensorFlow 的Windows的安装
1. 在前面我们装了 Anaconda Python 2.7,而 TensorFlow 需要 Python 3.5,不过两者在 Windows 下也可以共存,具体见:Windows下Anaconda2(Python2)和Anaconda3(Python3)的共存。
2. 按上文切换到 Python 3,然后一个命令就可以装好:tensorflow.org/versions/。例如 GPU 版本目前是:pip install --upgrade storage.googleapis.com。但是,你很可能会遇到 404 错误,那么可以把这个文件用迅雷下载下来,然后 pip install 文件名 即可。
3. 装完后检验一下。首先进 python 然后 import tensorflow 然后 hello = tf.constant('Hello, TensorFlow!') 然后 sess = tf.Session() 然后 print(sess.run(hello))。
4. 然后 python -m tensorflow.models.image.mnist.convolutional 测试训练 MNIST 模型(一开始也会下载数据文件,比较慢)。四、TensorFlow的Mac的安装
再看看 Mac 的安装。我是 OSX 10.11。
1.首先 sudo easy_install pip 然后 sudo easy_install --upgrade six 然后 pip install tensorflow-gpu 即可。
2. 可能需要再执行 sudo ln -s /usr/local/cuda/lib/libcuda.dylib /usr/local/cuda/lib/libcuda.1.dylib ,否则 import tensorflow 会报错。
3. 用一样的办法检验一下安装是否成功。五、训练策略网络
激动人心的时刻到了,我们开始真正训练 policy network。下面都以 Windows 下面的操作为例。
把网友做好的 AlphaGo v13 简化版下载下来:brilee/MuGo 。然后 pip install 了 argh 和 sgf。注意 gtp 要额外装:jtauber/gtp (下载下来后用 easy_install . 装)。
然后下载一些用于学习的棋谱。围棋棋谱的通用格式是 SGF。比如,就下载 KGS 的对局棋谱吧:u-go.net 。我没有统计过,不过上面大概有十万局吧。从原理上说,棋谱越多,训练的质量就越有保证;但是,棋谱中对弈者的水平参差不齐,如何控制这一变量,做过深度学习的朋友心中会有答案。本篇先不谈技术细节,我们先继续走。
下面提取棋谱的特征,并将其分类为训练集和测试集。先建立 data 子目录,把 SGF 拷贝进去。例如下载 2014 年的 13029 局棋谱,解压到 data 下面是 kgs-19-2014,那么就执行
python main.py preprocess data/kgs-19-2014
截至今天为止,你会发现它写的 chunk 比预想少很多,所以生成的训练数据很少。具体来说,棋谱的让子大于 4 会崩溃,棋谱没有写明贴目会崩溃,有时候棋谱里面的 [tt] 其实也代表 PASS,等等。做为作业,请自己一个个修复吧! SGF 格式的说明在此:SGF file format FF
再建立一个 tmp 目录,然后开始训练 1 个周期:
python main.py train processed_data --save-file=tmp\savedmodel --epochs=1 --logdir=logs\my_training_run
你会发现策略网络的预测准确率开始从 0 慢慢上升了! 然后可以随时继续训练,比如说继续训练 10 个周期就是:
python main.py train processed_data --read-file=tmp\savedmodel --save-file=tmp\savedmodel --epochs=10 --logdir=logs\my_training_run
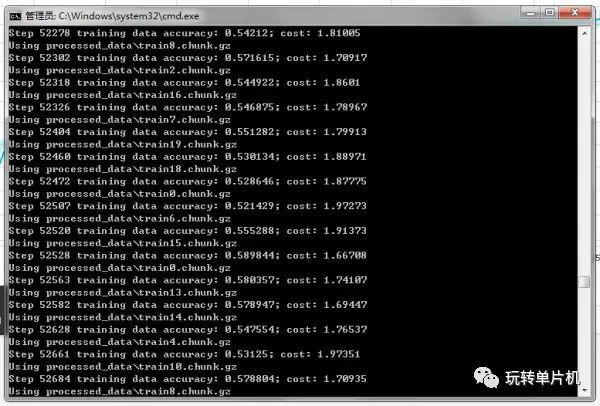
训练的时候,可以再开一个命令行,激活 python3,然后 tensorboard --logdir=logs 然后在浏览器打开 http://127.0.0.1:6006/ 可以看到训练的过程:

一直训练到准确率增加缓慢为止,应该可以到接近 60%。
测试一下走棋(如果你会 GTP 协议):python main.py gtp policy --read-file=tmp\savedmodel 这是纯网络输出。如果把 policy 改成 mcts 就是加入了蒙特卡洛树搜索的,棋力更高(但是截至今天为止,你执行会发现立刻退出,这位网友的程序 bug 真是太多了,我们以后再重写)。
如果不会 GTP,还是下载 GoGui 围棋图形界面吧: Download GoGui from SourceForge.net 。然后执行:"C:\Program Files (x86)\GoGui\gogui-twogtp.exe" -black "python main.py gtp policy --read-file=tmp\savedmodel" -white "C:\Program Files (x86)\GoGui\gogui-display" -size 19 -komi 7.5 -verbose -auto,但是截至今天为止,你会发现它很快就报错退出......
这是因为截至今天为止,代码有个 bug 是 strategies.py 的第 95 行的函数要改成 is_move_reasonable(position, move) 。然后......你亲手制造的小狗就可以运行了! 黑棋是小狗:

Behold,小狗已经学会了守角! 不过现在他还特别弱,因为没有搜索,容易死活出问题。
如果不会下围棋,让 GnuGo 来玩玩吧,下载链接:gnugo.baduk.org/,比如解压到 C:\gnugo\gnugo.exe ,然后执行:"C:\Program Files (x86)\GoGui\gogui.exe" -size 19 -computer-both -auto -program "C:\Program Files (x86)\GoGui\gogui-twogtp.exe -black ""C:\gnugo\gnugo.exe --level 1 --mode gtp"" -white ""python main.py gtp policy --read-file=tmp\savedmodel"" -games 1 -size 19 -alternate -sgffile gnugo -verbose" 即可。你会发现下到后面也会崩溃,如果打开 GTP Shell 看看,是因为小狗还无法理解对方的 PASS,哈哈。
六、神经网络在围棋中的历史
再次回顾 AlphaGo v13 的三大组件:
MCTS(蒙特卡洛树搜索)
CNN (卷积神经网络,包括:策略网络 policy network、快速走子网络 playout network、价值网络 value network)
RL (强化学习)在上世纪90年代初期,大家就已经开始实验将神经网络(当时是浅层的)与强化学习应用于棋类游戏。最著名的例子是西洋双陆棋 Backgammon 的 TD-Gammon,它在自我对弈了150万局后,就达到了相当强的棋力,摘选 Wikipedia 中的一段:
Backgammon expert Kit Woolsey found that TD-Gammon's positional judgement, especially its weighing of risk against safety, was superior to his own or any human's.
TD-Gammon's excellent positional play was undercut by occasional poor endgame play. The endgame requires a more analytic approach, sometimes with extensive lookahead. TD-Gammon's limitation to two-ply lookahead put a ceiling on what it could achieve in this part of the game. TD-Gammon's strengths and weaknesses were the opposite of symbolic artificial intelligence programs and most computer software in general: it was good at matters that require an intuitive "feel", but bad at systematic analysis.
简单地说,就是"大局观"特别强(比当时所有人类都强,不过,后来人也学习它的招法,人也进步了!),但是"官子弱"。这恰好和许多围棋 AI 给人的感觉完全一致。
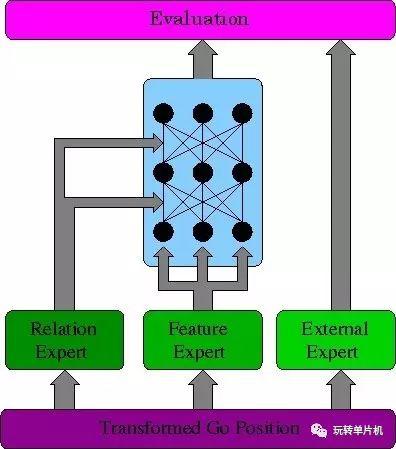
然而神经网络(浅层的)在围棋中的应用却遇到很大的困难。例如90年代就有一个神经网络围棋叫 NeuroGo:The Integration of A Priori Knowledge into a Go Playing Neural Network 它的架构(如下图)也经过不少考虑,但棋力很低,10K的水平:
七、策略网络的工作原理
究其原因,我们看策略网络的输入(很多年来大家使用的输入都大同小异,最重要的是把棋子按气的口数分类,如1口气的,2口气的,3口气的,4口和更多气的):
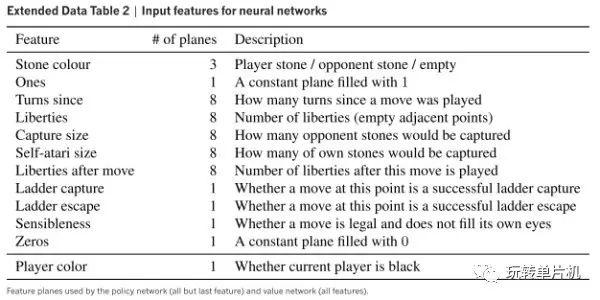
策略网络的目的,简单说是快速预测双方的下一手的位置,类似于棋手的第一感。实际上,策略网络的第一层是类似于这样的规则的集合(为方便非程序员理解,这里举一个特别的例子):
"如果这个位置的上面有一个1口气的对方棋子,左下区域的2口气以上的本方棋子密度为某某某,右边某某区域本方的棋子密度按气加权为某某某,......,那么将以上事实加权算出有xx%的几率在这里落子"看上去,这种规则更像是能预测某些局部的棋形情况,不像能准确地预测下一手。现代的围棋策略网络为何取得大的进展,是因为使用了 卷积神经网络 + 深度神经网络 的思想。
如果我们只看 AlphaGo v13 的第一层和最后一层神经网络,那么它的运作是:
使用了 192 条类似的规则(由棋谱自动训练出来)(规则的数量太少固然不行,太多也会慢同时容易走入误区),然后在全棋盘扫描每个点(这就是卷积神经网络的思想),计算由所有规则综合得到的权值。
再输入“1x1卷积核”网络(通俗地说,就是将每个点的上面算出的 192 种模式权值综合考虑,得出最终的落子几率),算出棋盘每个点作为走子的几率。如果也举个特别的例子,这类似于:
"如果要判断是否在这里走一个子,就会将【这里符合 A模式的程度】0.8,【这里符合 B模式的程度】0.4,【这里符合 C模式的程度】*(-0.2),等等等等,综合考虑,得出一个落子机率。"
上述具体的训练过程,就是每见到一个情况就加强这个情况的权值。因此越经常出现的情况就会越被加强。
八、深度神经网络为何有效
如果只有两层网络,在看棋谱时,对于对弈者的下一手的位置,只能达到 35% 左右的正确率:cs.utoronto.ca/
但是,通过使用深度神经网络,也就是多层的网络,AlphaGo v13 可以达到 55% 左右的预测正确率。这有两个原因:
一,是概念层面的。举例,人在选点时,会考虑附近的双方棋子的"厚薄",但"厚薄"是个高级概念,大致可以认为是棋块的"安定性"与"棋形"的结合。那么我们可以想象,如果第一层的规则,包括一部分专门负责"安定性"的规则,和一部分专门负责"棋形"的规则,再往上一层就可以通过加权考虑这两种规则的结果,得出类似"厚薄"的概念。然后再往上一层,就可以再运用之前得出的棋盘每个位置的"厚薄"情况,进行进一步的决策。
深度神经网络的最有趣之处在于,并不需要特别告诉它存在这样的概念的层次,它会自动从数据中形成这样的层次。
二,与棋盘和卷积神经网络的性质有关。第一层的规则,最好是局部的规则,因为这样的规则的泛化能力较高。譬如 AlphaGo v13 第一层使用的是 5x5 的局部,然后在第二层中再考虑 3x3 个 5x5 的局部,由于这些 5x5 的局部之间有重叠部分,就会形成一个 7x7 的局部。通过一层层往上加,最终可覆盖整个 19x19 的棋盘(如果你喜欢,可以继续往上加)。这符合我们的一种直觉:棋形会从里向外辐射一层层的影响,先看 5x5 ,然后看看周边的棋子就是 7x7 的情况,然后继续看下去。
九、新发展:残差网络
自然的问题是,如果这么说,是不是层越多就越好?
从前大家认为不是,因为太多层后很难训练,有时在训练集上的准确度已经会变差。
但是,如果仔细想想,这有点问题。我们不妨假设新加的一层就是一个不变变换,就是什么都不改变,就把上一层的输入做为输出。那么,此时的模型不会变好也不会变差。换而言之,增加层数,是永远不应该变差的!(这里的意思是,在训练集上的准确度不应该下降。在测试集上的准确度可能会由于过拟合而下降)
这就是 ResNet 残差网络的思想: 通过使用它,网络可以加到上千层也没有问题,几乎是一个免费的午餐:
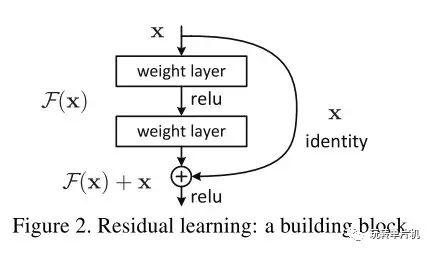
通过运用残差网络和少量 MCTS 模拟,策略网络的准确度可达 58% 以上:https://openreview.net/pdf?id=Bk67W4Yxl 。这近乎于理论最高值了,因为人的走棋不完美,同样的局面可以有不同的走法。
十、策略网络的弱点
然而策略网络是有弱点的。我在此更具体地说明几种情况。
第一,学习的棋谱数量有限,因此会有未见过的局面;同时,有时会知其然而不知其所以然,只学到了表面。这个问题很有趣,譬如,很多人发现 Zen6 (包括 DeepZenGo)有时会在征子上短路。下图是 2016/11/27 07:43 日 EWZGDXFEZ 与 Zen19L 在 KGS 的对局,黑棋是 Zen19L,走出了惊世骇俗的一步 M4,并认为自己的胜率高达 70% 以上:

结果被白棋直接在 N4 征死(同时胜率立刻掉到17%...)。这到底是为什么?我们可以打开 Zen6 的策略网络显示(Hotspots 菜单):
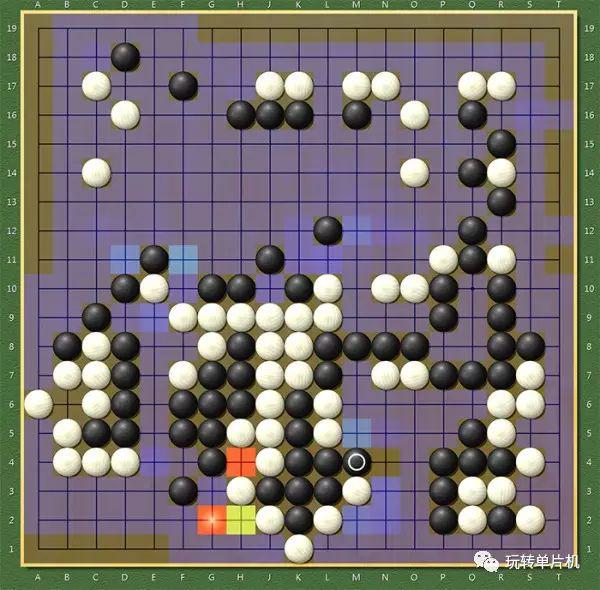
非常有趣。Zen6 认为白棋最可能的下一步是在 G2(概率大小是按红橙黄绿蓝紫排列,最不可能的是无色),而 N4 是它眼中白棋最不可能下的棋。它根本想不到白棋会走 N4。这个问题的成因是明显的:
在人类高手的对弈中,很少出现一方对另一方进行征子,因为另一方会预先避免对方征子成功。而策略网络在学习中,却不可能看到如此高的概念,它只能看到,如果有一方走出看似可以被征的棋形,另一方不会去征,于是,它所学到的,就是大家都不会去征对方的子。著名的第 78 手与此也有类似的原因(区别是隐蔽得多)。同样,机器很难理解人为什么会"保留",因为人"保留"的原因是另一个层次的(例如作为劫材)。当然,人的"保留"也不见得都对。
解决这个现象,初级的办法是加入手动的处理,更好的办法是通过自我对弈学习更多的局面。AlphaGo 比其它各路狗强大的重要原因,在于经过了上亿盘的左右互搏学习,见过的局面太多了。
第二,由于输入中缺乏对于多口气的精确区分(请思考为什么没有精确区分),可以说它不会精确数气,对于对杀和死活容易犯晕。这一般可以被蒙特卡洛树搜索纠正,但总会有纠正不了的情况。不过,虽然其它各路狗在此都经常会犯错,但 Master 却还没有被人抓到,有可能在于它已经学会有意避免这种局面,就像传说它会有意避免某些大型变化。
第三,靠感觉是不会精确收官和打劫,因此许多狗的官子和打劫有缺陷(换而言之,人可以靠官子和打劫逆转)。不过目前看来 AlphaGo 的新版已经专门为此做过额外处理,不会让人抓到这么明显的漏洞。我的一个猜测是,新版 AlphaGo 可能也建立了一个以"赢的子数"作为目标的价值网络,并且在适当的时候会参考它的结果。
许多人可能会很好奇,为什么各路狗都是用"胜率"而不是"赢的子数"作为目标。这是因为大家发现以"胜率"为标准,得到的胜率更高(这看似是废话,其实不是废话)。说到这个,我见过网上有人提为什么不在稳赢的时候改变贴目,尽量赢得更多一些,棋走得更好看;这个想法其实大家早就试过了,叫 Dynamic Komi 动态贴目,后果也是会稍微降低胜率。
不过,电脑的保守,有时候可以被人类利用。譬如,在电脑的棋有潜在缺陷的时候,可以先故意不走,等到收官阶段,电脑认为必胜(并且退让了很多)的时候再走,让电脑措手不及。最近陈耀烨就通过类似的办法连赢了国产狗好几盘,而 DeepZenGo 也被某位棋手抓到了一个漏洞连赢了好几盘(而这两位狗对付其它职业棋手的胜率已经相当高了)。围棋确实很有趣。我相信人机对抗并没有结束,还会继续下去,因为双方都会不断进步。
下面回答一个大家经常问的问题:强化学习在 AlphaGo 中究竟是怎么用的?比如说,SL策略网络,是怎么变成 RL 策略网络的?
十一、Policy Gradient:简单而有效
很有意思的是,很少见到有人回答上述问题(可能是因为 AlphaGo 论文在此写得很简略)。其实,这个问题的答案特别简单:
如果我赢了棋,就说明这次我选择的策略是正确的。所以可以对于这次所经历的每一个局面,都加强选择这局的走法的概率。
如果我输了棋,就说明这次我选择的策略是错误的。所以可以对于这次所经历的每一个局面,都减少选择这局的走法的概率。举个例子,比如说电脑左右互搏,黑棋开局走星位,白棋回应走小目,最后白棋输了,那么黑棋就加强开局走星位的概率(以及后续的每一步选择这局的走法的概率),白棋就减少在黑棋开局走星位的情况下走小目的概率(以及后续的每一步选择这局的走法的概率)。
等一下,这里好像有问题。这是不是太傻了?也许白棋并不是败在开局,而是败在中盘的某一步?也许黑棋并不是真的这次走对了策略,而是白棋看漏了一步(而且白棋如果走对是可以赢的)?
以上说的很正确。但是,反过来想,如果黑棋的走法可以让白棋后面打勺的概率增加,那也不错啊。另一方面,如果白棋发现自己目前的策略容易进入自己不容易掌握的局面,那么尽管确实可能有完美的招数隐藏在里面,那白棋也不妨一开始就去避免这种局面吧。而且,胜和负的影响可以相互抵消,所以在经过大量对局后,这个过程是比较稳定的。比如说如果某个开局的后续胜率经统计是50%,那它就不会被改变;但如果不是50%,这种改变就有一定道理。
这个过程,有点像人类棋手的“找到适合自己的棋风”的过程。毫无疑问,现在的 AlphaGo 已经找到了十分适合自己的棋风,它确实是会扬长避短的。
以上是最简单的 Policy Gradient 的例子,它的问题是有可能陷入局部的最优(对付自己有效,不代表对付其他人有效),因此 AlphaGo 论文中会建立一个对手池(包括整个进化过程中形成的所有策略),保证新策略尽量对于不同对手都有效。在这个基础上,可以做各种各样的改进,例如配合未来的价值网络,更清楚地看到自己的败着在哪里,而不是傻傻地把所有概率都同样修改 。
十二、Deepmind 的相关研究
其实 Deepmind 自创始以来就在做类似的研究,在此简单说说。经典的一系列论文是学会玩 Atari 游戏:
Playing Atari with Deep Reinforcement Learning
Human-level control through deep reinforcement learning
例如最经典的 Pong:

这里也有一个策略网络,它输入的是目前的屏幕图像(实际上要输入几幅图像,或者前后两幅图像的差,用于判断运动情况),输出的是此时应该往上移动的概率。用这里所说的训练方法就可以让它无师自通,自己学会玩游戏,最终达到相当高的水准(可以想象,这个学习过程会比较慢)。
但是如果我们仔细想想,这个办法恐怕很难自己学会玩好星际!一个重要原因是星际的决策中有太复杂的“层次结构”。因此尽管 Deepmind 此前说星际是下一个目标,目前我们尚未看到 Deepmind 在这方面发表的进展。如果真的成功实现,将是相当大的成就。
广告
关于立创商城
立创商城(WWW.SZLCSC.COM)是嘉立创集团旗下一家品种齐全、自营库存、质量有保障的电子元器件垂直商城,自建6000多平米现代化元器件仓库,现货库存超35000种。立创商城所有元器件均由原厂或代理商正规渠道采购,保证原装正品。
采购元器件推荐上立创商城,注册后可领取15元无门槛使用优惠券,如需业务编号请填写“N”,或直接点击阅读原文注册