дёҖгҖҒиҮӘиә«SPIж—¶й—ҙ
дё»иҠҜзүҮпјҡSTM32F072CBT6пјҲ48MпјүRFиҠҜзүҮпјҡSX1280(йҖҡиҝҮSPIйҖҡи®Ҝ)зҺҜеўғпјҡcubemxз”ҹжҲҗ+MDKV5
е…ідәҺSPIзҡ„йҖҡеёёзҡ„еә”з”ЁеҫҲз®ҖеҚ•пјҢзү№еҲ«жҳҜйҖҡиҝҮcubemxиҮӘеҠЁз”ҹжҲҗзҡ„д»Јз ҒпјҢиҝҷйҮҢе°ұдёҚиҝҮеӨҡд»Ӣз»ҚпјҢеҸҜиҮӘиЎҢзҷҫеәҰжҗңзҙўе…ідәҺSPIзҡ„ж•ҷзЁӢеҸҠзӣёе…іиө„ж–ҷгҖӮ
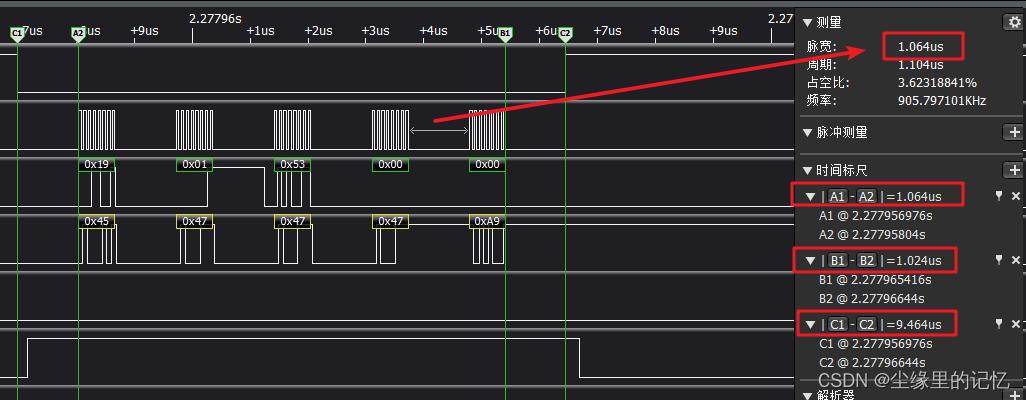
иҝҷеј еӣҫзүҮжҳҜйҖҡиҝҮcubemxз”ҹжҲҗзҡ„SPIд»Јз Ғзҡ„дёҖдёӘж•ҲжһңпјҲNSSиҪҜ件жҺ§еҲ¶+SPIдј иҫ“пјүпјҢдёҠиҝ°жҳҜд»ҝз…§HAL_SPI_TransmitReceiveпјҲпјүжӯӨеҮҪж•°еҸҲйҮҚж–°дҝ®ж”№еҲӣе»әдәҶдёҖдёӘBSP_SPI_TransmitReceiveпјҲпјүеҮҪж•°пјҢйҖҡиҝҮи°ғз”ЁBSP_SPI_TransmitReceiveпјҲпјүеҮҪж•°пјҢ然еҗҺжөӢеҮәзҡ„жіўеҪўпјҲе…ідәҺеҮҪж•°дҝ®ж”№зҡ„пјҢи§ҒдёӢйқўзҡ„е·ҘзЁӢи·Ҝеҫ„й“ҫжҺҘпјүгҖӮ
иҮідәҺдёәе•ҘдёҚз”ЁHALиҮӘиә«жҸҗдҫӣзҡ„HAL_SPI_TransmitReceiveпјҲпјүзҡ„еҮҪж•°пјҢжҳҜеӣ дёәжҲ‘еҸ‘зҺ°и°ғз”ЁиҝҷдёӘеҮҪж•°зҡ„ж—¶еҖҷдјҡйҖ жҲҗпјҢжҜҸдёӨдёӘеӯ—иҠӮеҗҺзҡ„й—ҙи·қдјҡжҜ”иҫғиҝңпјҢдҫӢпјҡеӯ—иҠӮ0е’Ңеӯ—иҠӮ1зӣёйҡ”жҜ”иҫғиҝ‘пјҢдҪҶжҳҜеӯ—иҠӮ1е’Ңеӯ—иҠӮ2йҡ”еҫ—жҢәиҝңзҡ„гҖӮ
иҜҙиҝңдәҶпјҢеӣһеҲ°дё»йўҳпјҢйҖҡиҝҮдёҠйқўеӣҫзүҮпјҢеҸҜзҹҘеӯ—иҠӮдёҺеӯ—иҠӮй—ҙи·қзҰ»еӨ§жҰӮдёә1.0usе·ҰеҸіпјҢ并且NSSжӢүдҪҺжӢүй«ҳдёҺж•°жҚ®дј иҫ“зҡ„ж—¶й—ҙд№ҹеӨ§жҰӮ1usпјҢеҸ‘йҖҒ5дёӘеӯ—иҠӮзҡ„ж•°жҚ®пјҢSPIиҮіе°‘йңҖиҰҒ9.46usгҖӮ
дәҢгҖҒеҜ№жҜ”SPIж—¶й—ҙиҝҷдёӘж•°жҚ®иҜҙе®һиҜқжҲ‘и§үзҡ„д№ҹиҝҳжҢәдёҚй”ҷзҡ„пјҢзӣҙеҲ°жҲ‘зӘҒ然еҸ‘зҺ°ж ·жңәSPIзҡ„йҖҹеәҰпјҢдёӨеӯ—иҠӮй—ҙи·қжҺ§еҲ¶еңЁnsзә§еҲ«пјҢеҰӮеӣҫ
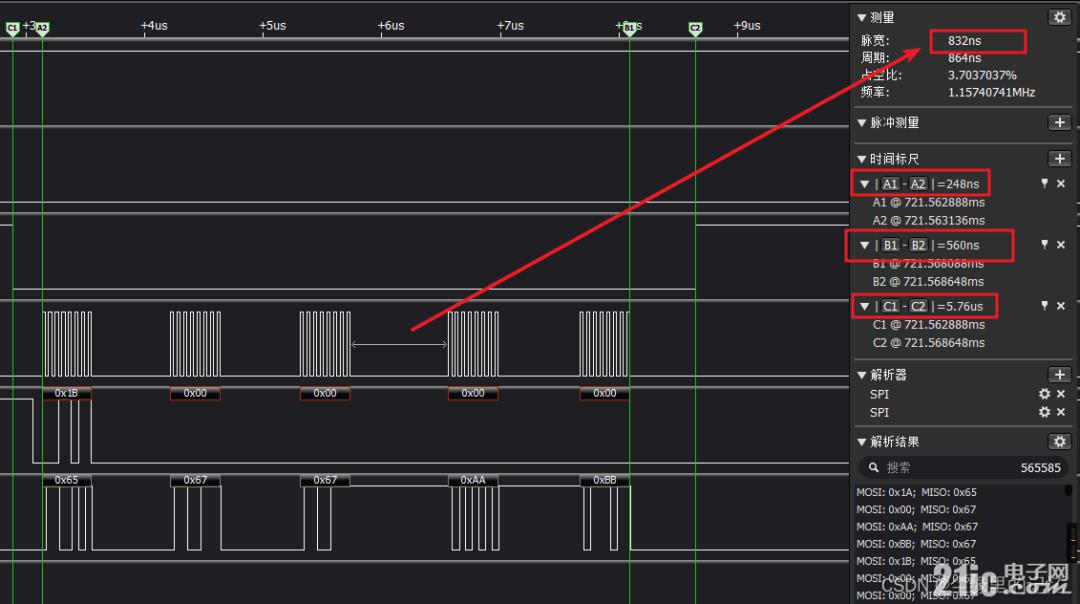
дёҠеӣҫеҗҢж ·жҳҜеҸ‘йҖҒ5еӯ—иҠӮзҡ„ж•°жҚ®пјҢеӯ—иҠӮй—ҙи·қжҺ§еҲ¶еңЁ832ns,дёӢжӢүNSSеҲ°ж•°жҚ®иҫ“248nsпјҢж•°жҚ®иҫ“еҮәе®ҢеҲ°дёҠжӢү560ns,ж•ҙдҪ“еҸ‘йҖҒ5еӯ—иҠӮйңҖиҰҒ5.7usгҖӮ
еҜ№жҜ”жҲ‘д№ӢеүҚзҡ„еҸӮж•°пјҢдёҖдёӘжҳҜеӯ—иҠӮй—ҙи·қдёҖдёӘжҳҜзәіз§’дёҖдёӘжҳҜжҜ«з§’пјҢиҝҳжңүжҖ»зҡ„еҸ‘йҖҒж—¶й—ҙпјҢж ·еӯҗеҸ‘йҖҒж—¶й—ҙеӨ§жҰӮе°ұжҲ‘зҡ„1/2гҖӮ
еӣ дёәжҲ‘иҝҷдёӘдј иҫ“еҜ№ж—¶й—ҙиҰҒжұӮиҫғй«ҳпјҢжүҖд»ҘжғізқҖд№ҹе°Ҷж—¶й—ҙе°ҪйҮҸеҮҸе°‘гҖӮ
дёүгҖҒе°қиҜ•еҮҸе°‘еӯ—иҠӮй—ҙи·қж—¶й—ҙ
1.еҲқжӯҘжөӢиҜ•жҖқи·Ҝ
йҖҡиҝҮеҜ№жҜ”ж ·жңәSPIзҡ„йҖҹеәҰпјҢеҸ‘зҺ°жңҖдё»иҰҒзҡ„жҳҜеӯ—иҠӮй—ҙи·қиҫғзҹӯпјҢйӮЈд№Ҳзј©зҹӯиҝҷдёӘж—¶й—ҙпјҢжҲ‘йҰ–е…ҲжғіеҲ°дәҶзҡ„жҳҜSPI+DMAиҝӣиЎҢдј иҫ“пјҢ然еҗҺе°ұйҖҡиҝҮcubemxзӣҙжҺҘз”ҹжҲҗдәҶдёҖSPI+DMAзҡ„й…ҚзҪ®пјҢ然еҗҺйҖҡиҝҮиҪҜ件жҺ§еҲ¶пјҢе…·дҪ“жөӢиҜ•д»Јз ҒеҰӮдёӢпјҡ
while (1)
{
/* USER CODE END WHILE */
HAL_GPIO_WritePin(GPIOA,GPIO_PIN_15,GPIO_PIN_RESET);
HAL_SPI_TransmitReceive_DMA(&hspi1,txbuff,rxbuff,8);
HAL_GPIO_WritePin(GPIOA,GPIO_PIN_15,GPIO_PIN_SET);
HAL_GPIO_TogglePin(LED_Red_GPIO_Port,LED_Red_Pin);
HAL_Delay(50);
/* USER CODE BEGIN 3 */
}еңЁwhileдёӯе‘ЁжңҹиҝӣиЎҢиҜ»еҶҷSPIж•°жҚ®пјҢдҪҶжҳҜеҸ‘зҺ°ж•°жҚ®дёҚеҜ№пјҢжөӢиҜ•зҺ°иұЎеҰӮдёӢ

еңЁдёҠеӣҫзҡ„жөӢиҜ•зҺ°иұЎдёӯпјҢNSSе·Із»ҸжӢүдҪҺдәҶпјҢдҪҶжҳҜиҰҒзӯүдёҖж®өж—¶й—ҙжүҚдјҡиҝӣиЎҢж•°жҚ®дј иҫ“пјҢиҖҢдё”ж•°жҚ®иҝҳжңӘдј иҫ“е®ҢжҲҗпјҢNSSе°ұжӢүй«ҳдәҶпјҢиҝҷдёӘзҺ°иұЎе°ұжңүй—®йўҳдәҶгҖӮй’ҲеҜ№NSSеј•и„ҡе’Ңж•°жҚ®дј иҫ“й”ҷејҖзҡ„зҺ°иұЎпјҢеўһеҠ дәҶдёҖдёӘзӯүеҫ…дј иҫ“е®ҢеҶҚжӢүй«ҳзҡ„д»Јз Ғ
while (1)
{
/* USER CODE END WHILE */
HAL_GPIO_WritePin(GPIOA,GPIO_PIN_15,GPIO_PIN_RESET);
HAL_SPI_TransmitReceive_DMA(&hspi1,txbuff,rxbuff,8);
while(__HAL_DMA_GET_COUNTER(&hdma_spi1_rx)!=0);
HAL_GPIO_WritePin(GPIOA,GPIO_PIN_15,GPIO_PIN_SET);
HAL_GPIO_TogglePin(LED_Red_GPIO_Port,LED_Red_Pin);
HAL_Delay(50);
/* USER CODE BEGIN 3 */
}з»“жһңеҰӮдёӢпјҡ
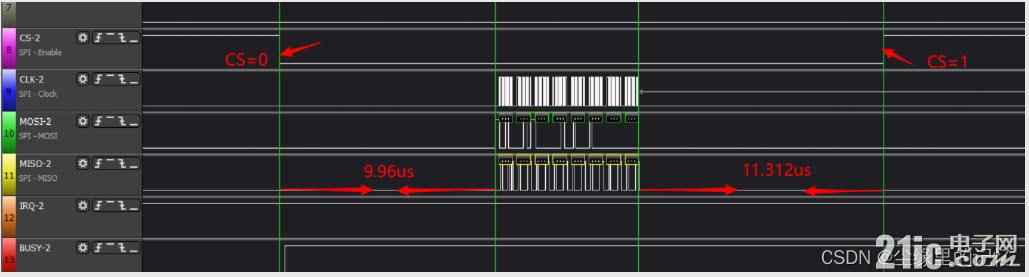
зҺ°еңЁж•°жҚ®дј иҫ“жҳҜеңЁNSSжӢүдҪҺиҢғеӣҙеҶ…дәҶпјҢдҪҶжҳҜNSSжӢүдҪҺеҲ°ж•°жҚ®дј иҫ“жңү9.96usпјҢж•°жҚ®дј иҫ“е®ҢеҲ°NSSжӢүй«ҳд№ҹжңү11.312usпјҢеӯ—иҠӮй—ҙи·қеҖ’жҳҜеҮҸе°‘дәҶдёҚе°‘пјҢиҮіе°‘иҜҒжҳҺSPI+DMAиҝҷжқЎи·Ҝеә”иҜҘжҳҜжІЎй—®йўҳзҡ„пјҢеҸҜд»ҘеҮҸе°‘ж•°жҚ®дј иҫ“зҡ„ж—¶й—ҙгҖӮ
2.еҶҚж¬ЎжөӢиҜ•
й’ҲеҜ№дёҠдёҖж¬ЎжөӢиҜ•пјҢеҸ‘зҺ°NSSзҡ„жӢүй«ҳжӢүдҪҺеҲ°ж•°жҚ®дј иҫ“йңҖиҰҒиҫғй•ҝзҡ„ж—¶й—ҙпјҢжҲ‘е°ұжғідјҡдёҚдјҡжҳҜиҪҜ件жҺ§еҲ¶NSSеӨӘж…ўдәҶпјҢеҸҰеӨ–з”ұдәҺSPIжҳҜDMAиҝӣиЎҢдј иҫ“зҡ„пјҢе°ұжңүеҸҜиғҪеҜјиҮҙSPIдј иҫ“е’ҢжҺ§еҲ¶NSSзҡ„ж“ҚдҪңжІЎиҫҫеҲ°еҗҢжӯҘпјҢжүҖд»Ҙе°ұе°ҶSPI+DMAзҡ„иҪҜ件жҺ§еҲ¶NSS ж”№жҲҗдәҶ 硬件жҺ§еҲ¶NSS гҖӮ
/* SPI1 init function */
void MX_SPI1_Init(void)
{
hspi1.Instance = SPI1;
hspi1.Init.Mode = SPI_MODE_MASTER; //и®ҫзҪ®SPIе·ҘдҪңжЁЎејҸпјҢи®ҫзҪ®дёәдё»жЁЎејҸ
hspi1.Init.Direction = SPI_DIRECTION_2LINES; //и®ҫзҪ®SPIеҚ•еҗ‘жҲ–иҖ…еҸҢеҗ‘зҡ„ж•°жҚ®жЁЎејҸ:SPIи®ҫзҪ®дёәеҸҢзәҝжЁЎејҸ
hspi1.Init.DataSize = SPI_DATASIZE_8BIT; //и®ҫзҪ®SPIзҡ„ж•°жҚ®еӨ§е°Ҹ:SPIеҸ‘йҖҒжҺҘ收8дҪҚеё§з»“жһ„
hspi1.Init.CLKPolarity = SPI_POLARITY_LOW; //дёІиЎҢеҗҢжӯҘж—¶й’ҹзҡ„з©әй—ІзҠ¶жҖҒдёәдҪҺз”өе№і
hspi1.Init.CLKPhase = SPI_PHASE_1EDGE; //дёІиЎҢеҗҢжӯҘж—¶й’ҹзҡ„第дёҖдёӘи·іеҸҳжІҝпјҲдёҠеҚҮжҲ–дёӢйҷҚпјүж•°жҚ®иў«йҮҮж ·
hspi1.Init.NSS = SPI_NSS_HARD_INPUT; //NSSдҝЎеҸ·з”ұиҪҜ件жҺ§еҲ¶ SPI_NSS_HARD_OUTPUT SPI_NSS_SOFT
hspi1.Init.BaudRatePrescaler = SPI_BAUDRATEPRESCALER_4; //е®ҡд№үжіўзү№зҺҮйў„еҲҶйў‘зҡ„еҖј:жіўзү№зҺҮйў„еҲҶйў‘еҖјдёә4
hspi1.Init.FirstBit = SPI_FIRSTBIT_MSB; //жҢҮе®ҡж•°жҚ®дј иҫ“д»ҺMSBдҪҚиҝҳжҳҜLSBдҪҚејҖе§Ӣ:ж•°жҚ®дј иҫ“д»ҺMSBдҪҚејҖе§Ӣ
hspi1.Init.TIMode = SPI_TIMODE_DISABLE; //е…ій—ӯTIжЁЎејҸ
hspi1.Init.CRCCalculation = SPI_CRCCALCULATION_DISABLE; //е…ій—ӯ硬件CRCж ЎйӘҢ
hspi1.Init.CRCPolynomial = 7; //CRCеҖји®Ўз®—зҡ„еӨҡйЎ№ејҸ
hspi1.Init.CRCLength = SPI_CRC_LENGTH_DATASIZE;
hspi1.Init.NSSPMode = SPI_NSS_PULSE_ENABLE;//SPI_NSS_PULSE_DISABLE; //
if (HAL_SPI_Init(&hspi1) != HAL_OK)
{
_Error_Handler(__FILE__, __LINE__);
}
}
void HAL_SPI_MspInit(SPI_HandleTypeDef* spiHandle)
{
GPIO_InitTypeDef GPIO_InitStruct;
if(spiHandle->Instance==SPI1)
{
/* USER CODE BEGIN SPI1_MspInit 0 */
/* USER CODE END SPI1_MspInit 0 */
/* SPI1 clock enable */
__HAL_RCC_SPI1_CLK_ENABLE();
/**SPI1 GPIO Configuration
PB3 ------> SPI1_SCK
PB4 ------> SPI1_MISO
PB5 ------> SPI1_MOSI
*/
GPIO_InitStruct.Pin = GPIO_PIN_15;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Pull = GPIO_NOPULL;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF0_SPI1;
HAL_GPIO_Init(GPIOA, &GPIO_InitStruct);
GPIO_InitStruct.Pin = A7106_SCK_Pin|A7106_MISO_Pin|A7106_MOSI_Pin;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Pull = GPIO_NOPULL;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF0_SPI1;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
/* SPI1 DMA Init */
/* SPI1_TX Init */
hdma_spi1_tx.Instance = DMA1_Channel3; //йҖҡйҒ“йҖүжӢ©
hdma_spi1_tx.Init.Direction = DMA_MEMORY_TO_PERIPH; //еӯҳеӮЁеҷЁеҲ°еӨ–и®ҫ
hdma_spi1_tx.Init.PeriphInc = DMA_PINC_DISABLE; //еӨ–и®ҫйқһеўһйҮҸжЁЎејҸ
hdma_spi1_tx.Init.MemInc = DMA_MINC_ENABLE; //еӯҳеӮЁеҷЁеўһйҮҸжЁЎејҸ
hdma_spi1_tx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE; //еӨ–и®ҫж•°жҚ®й•ҝеәҰ:8дҪҚ
hdma_spi1_tx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE; //еӯҳеӮЁеҷЁж•°жҚ®й•ҝеәҰ:8дҪҚ
hdma_spi1_tx.Init.Mode = DMA_NORMAL; //DMAжҷ®йҖҡжЁЎејҸ
hdma_spi1_tx.Init.Priority = DMA_PRIORITY_HIGH;
if (HAL_DMA_Init(&hdma_spi1_tx) != HAL_OK)
{
_Error_Handler(__FILE__, __LINE__);
}
__HAL_LINKDMA(spiHandle,hdmatx,hdma_spi1_tx);
/* SPI1_RX Init */
hdma_spi1_rx.Instance = DMA1_Channel2;
hdma_spi1_rx.Init.Direction = DMA_PERIPH_TO_MEMORY;
hdma_spi1_rx.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_spi1_rx.Init.MemInc = DMA_MINC_ENABLE;
hdma_spi1_rx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_spi1_rx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
hdma_spi1_rx.Init.Mode = DMA_NORMAL;
hdma_spi1_rx.Init.Priority = DMA_PRIORITY_HIGH;
if (HAL_DMA_Init(&hdma_spi1_rx) != HAL_OK)
{
_Error_Handler(__FILE__, __LINE__);
}
__HAL_LINKDMA(spiHandle,hdmarx,hdma_spi1_rx);
/* USER CODE BEGIN SPI1_MspInit 1 */
/* USER CODE END SPI1_MspInit 1 */
}
}硬件жҺ§еҲ¶NSSпјҢжғізқҖи®©е…¶иҮӘеҠЁжӢүй«ҳжӢүдҪҺпјҢдҪҶжҳҜжөӢиҜ•еҸ‘зҺ°пјҢжҜҸеҸ‘дёҖдёӘеӯ—иҠӮNSSеј•и„ҡе°ұиҮӘеҠЁжӢүй«ҳдәҶпјҢиҝҷе°ұеҜјиҮҙдәҶиҜ»еҸ–зҡ„ж•°жҚ®жҳҜжңүй—®йўҳзҡ„пјҢе…·дҪ“зҺ°иұЎеҰӮдёӢпјҡ
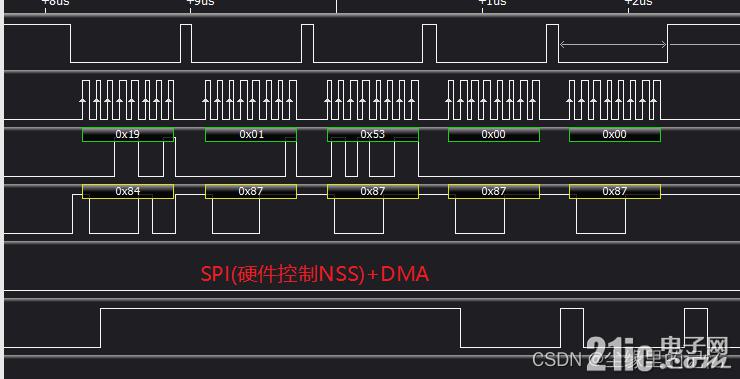
дёҠеӣҫзҡ„зҺ°иұЎпјҢжҜҸдёӘеӯ—иҠӮйғҪиҝӣиЎҢжӢүй«ҳдәҶпјҢйӮЈеҜ№дәҺдёҖеҢ…ж•°жҚ®еӨ§дәҺ1еӯ—иҠӮзҡ„иҜқпјҢйӮЈд№Ҳе°ұдјҡжңүй—®йўҳзҡ„пјҢSPIзҡ„ж•°жҚ® = еӨ–и®ҫең°еқҖ + иҜҘең°еқҖзҡ„е‘Ҫд»Ө(жҲ‘зҡ„зҗҶи§Ј)жүҖд»Ҙй’ҲеҜ№дёҠеӣҫпјҢжҲ‘жғізқҖе°ұеҰӮдҪ•и®©NSSжӢүй«ҳзҡ„ж“ҚдҪңе’ҢеҸ‘йҖҒзҡ„ж•°жҚ®зӣёе…іиҒ”пјҢеҚідёҚи®©д»–жҜҸдёӘеӯ—иҠӮйғҪиҮӘеҠЁжӢүй«ҳдёәжӯӨпјҢз ”з©¶дәҶеҘҪд№…пјҢеҗҢж—¶д№ҹеҸ‘иҝҮеҘҪеҮ дёӘеё–еӯҗпјҢйғҪжІЎжңүжүҫеҲ°зӣёе…ізҡ„иө„ж–ҷ
-------------------------------еҚЎдё»дәҶ---------------------------------------------------------------------------------------------
еңЁиҝҷдёӘйҳ¶ж®өеҚЎдәҶжҢәд№…зҡ„пјҢеҗҺйқўд№ҹе°ұжІЎз®ЎSPI+DMAзҡ„еә”з”ЁдәҶпјҢзӣҙеҲ°еҗҺйқўз©әй—ІдәҶеңЁжҺҘзқҖйҮҚж–°жӢҝиө·иҝҷдёӘSPI+DMAзҡ„ж“ҚдҪңгҖӮ
3.й—ҙйҡ”дёӨдёӘжңҲеҗҺзҡ„еҶҚж¬Ўе°қиҜ•
еңЁжҲ‘еҸ‘зҡ„е…ідәҺSPI+DMAзҡ„жұӮеҠ©её–еӯҗдёҠпјҢжҲ‘зңӢеҲ°жҺЁиҚҗиҜҙз”ЁиҪҜ件NSSпјҢеҗҢж—¶жҲ‘д№ҹд»”з»Ҷз ”з©¶дәҶдёӢж ·жңәзҡ„SPIжіўеҪўпјҢеҸ‘зҺ°д»–жңүдёӨи·ҜSPIж•°жҚ®гҖӮ
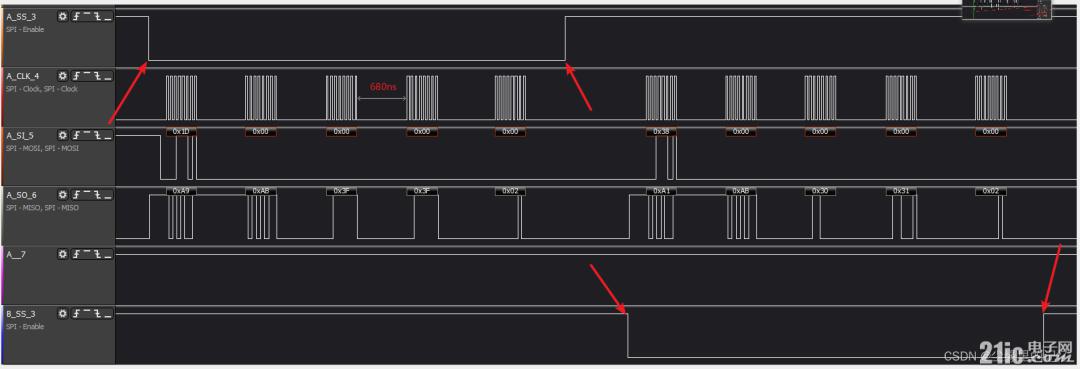
дҪҶжҳҜеңЁеҲқжӯҘжөӢиҜ•ж—¶пјҢиҪҜ件жҺ§еҲ¶NSSпјҢеҮәзҺ°й”ҷдҪҚй—®йўҳпјҢжүҖд»ҘеҜ№иҪҜ件жҺ§еҲ¶иҝҳжҳҜжңүдәӣжҖҖз–‘зҡ„пјҢзӣҙеҲ°жҲ‘еңЁеё–еӯҗдёҠзңӢеҲ° жӯЈеёёжқҘи®ІпјҢйӮЈдёӘNSSжҜҸдёӘеӯ—иҠӮжҠ¬й«ҳдёҖдёӘж—¶й’ҹж—¶й—ҙжҳҜжӯЈеёёзҡ„ж“ҚдҪңпјҢжҜҸдёӘеӯ—иҠӮNSSжҠ¬й«ҳжҳҜжӯЈеёёж“ҚдҪңпјҢйӮЈд№ҲжҲ‘жғіз”ЁзЎ¬д»¶жҺ§еҲ¶NSSпјҢи®©е…¶и·ҹйҡҸдј иҫ“зҡ„ж•°жҚ®иҝӣиЎҢиҮӘеҠЁжӢүй«ҳжӢүдҪҺе°ұиЎҢдёҚйҖҡдәҶпјҢжҖқи·Ҝжңүй—®йўҳдәҶгҖӮ
зҺ°еңЁејҖе§Ӣдё“з ”иҪҜ件жҺ§еҲ¶NSSпјҢиҫҫеҲ°SPI+DMAзҡ„ж“ҚдҪңдәҶпјҢеңЁжөӢиҜ•1дёӯпјҢжҡҙйңІзҡ„й—®йўҳжҳҜNSSжӢүй«ҳзҡ„еӨӘеҝ«дәҶпјҢйӮЈд№ҲжҚўдёӘжҖқи·ҜпјҢиғҪдёҚиғҪи®©д»–дј иҫ“е®ҢжҲҗе°ұиҮӘеҠЁжӢүй«ҳе‘ўпјҢиҝҷжҳҜеҸҜд»Ҙзҡ„пјҢDMAдёӯж–ӯдёӯжӯЈеҘҪе°ұжңүдёҖдёӘдј иҫ“е®ҢжҲҗзҡ„ж Үеҝ—пјҢйӮЈжҲ‘е°ұеҲ©з”ЁдёҠиҝҷдёӘж Үеҝ—пјҢеңЁдёӯж–ӯдёӯи®©е…¶жӢүй«ҳNSSгҖӮ
void DMA1_Channel2_3_IRQHandler(void)
{
/* USER CODE BEGIN DMA1_Channel2_3_IRQn 0 */
/* USER CODE END DMA1_Channel2_3_IRQn 0 */
HAL_DMA_IRQHandler(&hdma_spi1_rx);
HAL_DMA_IRQHandler(&hdma_spi1_tx);
/* USER CODE BEGIN DMA1_Channel2_3_IRQn 1 */
if(__HAL_DMA_GET_IT_SOURCE(&hdma_spi1_rx, DMA_IT_TC)){
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_SET);
}
/* USER CODE END DMA1_Channel2_3_IRQn 1 */
}жүҖд»ҘжҲ‘и·іеҲ°HAL_SPI_TransmitReceive_DMA()еҮҪж•°йҮҢпјҢеңЁејҖеҗҜDMAеүҚпјҢеўһеҠ дәҶжӢүдҪҺNSSзҡ„ж“ҚдҪң
зҺ°еңЁNSSжӢүдҪҺзҡ„ж“ҚдҪңпјҢж”ҫеҲ°HALжҸҗдҫӣзҡ„HAL_SPI_TransmitReceive_DMA()еҮҪж•°йҮҢпјӣNSSжӢүй«ҳзҡ„ж“ҚдҪңпјҢеңЁDMAдј иҫ“е®ҢжҲҗдёӯж–ӯдёӯпјӣжөӢиҜ•ж•Ҳжһңпјҡ
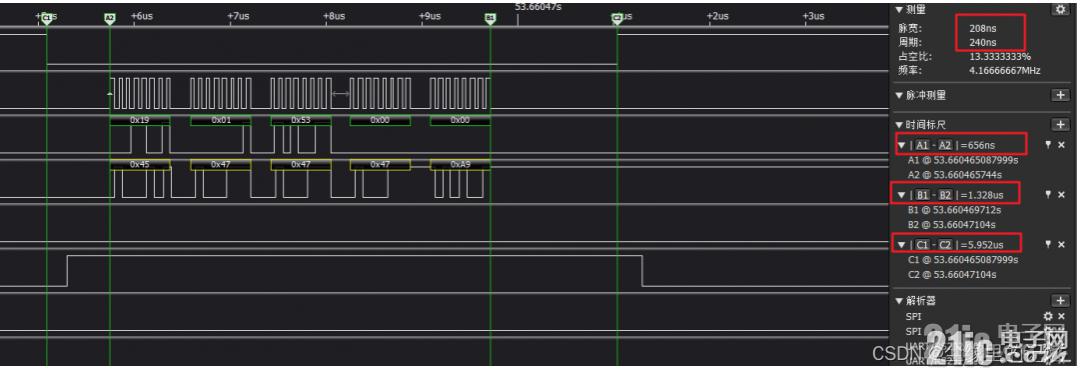
иҝҷдёӘж•ҲжһңжҳҜдёҚй”ҷзҡ„пјҢеӯ—иҠӮй—ҙи·қжҳҜ208ns,жӢүдҪҺеҲ°ж•°жҚ®дј иҫ“656ns,ж•°жҚ®дј иҫ“е®ҢеҲ°жӢүй«ҳ1.328us,еҸ‘йҖҒ5дёӘеӯ—иҠӮйңҖиҰҒ5.952usзҡ„ж—¶й—ҙпјҢиҝҷдёӘж—¶й—ҙзӣёжҜ”дәҺд№ӢеүҚе·Із»ҸжҸҗеҚҮжҢәеӨҡзҡ„дәҶпјҢе°ұжҳҜж•°жҚ®дј иҫ“е®ҢеҲ°жӢүй«ҳж—¶й—ҙзЁҚеҫ®жңүзӮ№й•ҝгҖӮ
еӣӣгҖҒе®һзҺ°SPI+DMAдј иҫ“пјҲеҮҸе°‘дј иҫ“ж—¶й—ҙпјү
еңЁжңҖеҗҺдёҖж¬ЎжөӢиҜ•дёӯпјҢж—¶й—ҙе·Із»ҸдёҚй”ҷдәҶпјҢе°ұжҳҜзЁҚеҫ®жңүзӮ№з‘•з–өпјҢдәҺжҳҜеңЁиҝӣиЎҢдҝ®ж”№пјҢеңЁ
HAL_DMA_IRQHandler(&hdma_spi1_tx);йҮҢйқўеҜ№NSSиҝӣиЎҢжӢүй«ҳгҖӮ
void HAL_DMA_IRQHandler(DMA_HandleTypeDef *hdma)
{
***************зңҒз•Ҙ**************
/* Transfer Complete Interrupt management ***********************************/
else if ((RESET != (flag_it & (DMA_FLAG_TC1 << hdma->ChannelIndex))) && (RESET != (source_it & DMA_IT_TC)))
{
if((hdma->Instance->CCR & DMA_CCR_CIRC) == 0U)
{
/* Disable the transfer complete & transfer error interrupts */
/* if the DMA mode is not CIRCULAR */
hdma->Instance->CCR &= ~(DMA_IT_TC | DMA_IT_TE);
/* Change the DMA state */
hdma->State = HAL_DMA_STATE_READY;
}
/* Clear the transfer complete flag */
hdma->DmaBaseAddress->IFCR = DMA_FLAG_TC1 << hdma->ChannelIndex;
/*nss up*/
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_SET);
/* Process Unlocked */
__HAL_UNLOCK(hdma);
if(hdma->XferCpltCallback != NULL)
{
/* Transfer complete callback */
hdma->XferCpltCallback(hdma);
}
}
***************зңҒз•Ҙ**************
}еҸ‘зҺ°е°ҶNSSж”ҫеңЁиҝҷйҮҢпјҢж—¶й—ҙжҳҜжӣҙзҹӯзҡ„
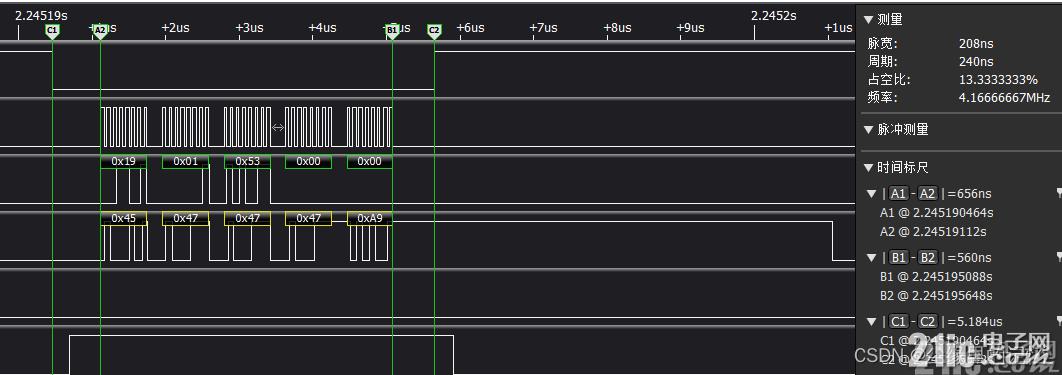
ж•°жҚ®дј иҫ“е®ҢеҲ°жӢүй«ҳNSSпјҢе·Із»ҸйҷҚдҪҺеҲ°560nsдәҶпјҢдёәдәҶйҖӮй…Қе…¶д»–зҡ„DMAдёӯж–ӯпјҢжң¬жғіеңЁHAL_DMA_IRQHandler()йҮҢйқўеўһеҠ if еҲӨж–ӯпјҢеҶҚжӢүй«ҳNSSпјҢдҪҶжҳҜеҸ‘зҺ°еўһеҠ дәҶеҲӨж–ӯпјҢж•°жҚ®дј иҫ“е®ҢеҲ°жӢүй«ҳNSSиҝҷйҮҢзҡ„ж—¶й—ҙеҸҲеҸҳжҲҗдәҶus,дәҺжҳҜзҙўжҖ§еӨҚHAL_DMA_IRQHandler()иҝҷдёӘеҮҪж•°пјҢеңЁйҮҢйқўиҝӣиЎҢжӢүй«ҳNSSзҡ„ж“ҚдҪңпјҢ并еҜ№еҮҪж•°йҮҚе‘ҪеҗҚпјҢеҸӘиғҪSPI_DMAи°ғз”ЁгҖӮ
е®һзҺ°жӯҘйӘӨдёҖ
еҲӣе»әеұһдәҺиҮӘе·ұзҡ„HAL_DMA_SPIиҜ»еҶҷеҮҪж•°
/*
* еӨҚеҲ¶HAL_SPI_TransmitReceive_DMA()еҮҪж•°пјҢеңЁејҖеҗҜDMAеүҚпјҢжӢүдҪҺNSSеј•и„ҡ
*/
HAL_StatusTypeDef HAL_SPI_MY_TransmitReceive_DMA(SPI_HandleTypeDef *hspi, uint8_t *pTxData, uint8_t *pRxData,uint16_t Size)
{
***************************
******************зңҒз•Ҙ**************
/* Set the SPI Tx DMA transfer complete callback as NULL because the communication closing is performed in DMA reception complete callback */
hspi->hdmatx->XferHalfCpltCallback = NULL;
hspi->hdmatx->XferCpltCallback = NULL;
hspi->hdmatx->XferErrorCallback = NULL;
hspi->hdmatx->XferAbortCallback = NULL;
/* Enable the Tx DMA Stream/Channel */
HAL_DMA_Start_IT(hspi->hdmatx, (uint32_t)hspi->pTxBuffPtr, (uint32_t)&hspi->Instance->DR, hspi->TxXferCount);
/* Check if the SPI is already enabled */
if ((hspi->Instance->CR1 & SPI_CR1_SPE) != SPI_CR1_SPE)
{
/* Enable SPI peripheral */
__HAL_SPI_ENABLE(hspi);
}
/* Enable the SPI Error Interrupt Bit */
__HAL_SPI_ENABLE_IT(hspi, (SPI_IT_ERR));
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_RESET);
/* Enable Tx DMA Request */
SET_BIT(hspi->Instance->CR2, SPI_CR2_TXDMAEN);
error :
/* Process Unlocked */
__HAL_UNLOCK(hspi);
return errorcode;
}иҝҷдёӘеҮҪж•°еҸӘжҳҜеҚ•зәҜеӨҚеҲ¶HAL_SPI_TransmitReceive_DMA()еҮҪж•°пјҢ然еҗҺеңЁејҖеҗҜDMAеүҚпјҢжӢүдҪҺNSSеј•и„ҡпјҢиҝҷж ·е°ұиғҪе°ҪйҮҸеҮҸе°‘еҜ№еә“зҡ„дҝ®ж”№пјҢеҗҢж—¶еңЁNSSжӣҙжҚўеј•и„ҡеҗҺпјҢд№ҹеҸҜд»Ҙжӣҙж–№дҫҝдҝ®ж”№NSSеј•и„ҡ
е®һзҺ°жӯҘйӘӨдәҢ
еҲӣе»әеұһдәҺиҮӘе·ұзҡ„HAL_DMA_SPIдёӯж–ӯеҮҪж•°
/*
* еңЁit.cдёӯпјҢиҰҒе…Ҳи°ғз”Ё
HAL_DMA_IRQHandler(&hdma_spi1_rx);
HAL_SPI1_TX_DMA_IRQHandler(&hdma_spi1_tx);//еңЁжӯӨеҮҪж•°дёӯдјҡеҜ№NSSеј•и„ҡжӢүй«ҳ
*/
void HAL_SPI1_TX_DMA_IRQHandler(DMA_HandleTypeDef *hdma)
{
*****************зңҒз•Ҙ*************
/* Transfer Complete Interrupt management ***********************************/
else if ((RESET != (flag_it & (DMA_FLAG_TC1 << hdma->ChannelIndex))) && (RESET != (source_it & DMA_IT_TC)))
{
if((hdma->Instance->CCR & DMA_CCR_CIRC) == 0U)
{
/* Disable the transfer complete & transfer error interrupts */
/* if the DMA mode is not CIRCULAR */
hdma->Instance->CCR &= ~(DMA_IT_TC | DMA_IT_TE);
/* Change the DMA state */
hdma->State = HAL_DMA_STATE_READY;
}
/* Clear the transfer complete flag */
hdma->DmaBaseAddress->IFCR = DMA_FLAG_TC1 << hdma->ChannelIndex;
/*nss up*/
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_SET);
/* Process Unlocked */
__HAL_UNLOCK(hdma);
if(hdma->XferCpltCallback != NULL)
{
/* Transfer complete callback */
hdma->XferCpltCallback(hdma);
}
}
*****************зңҒз•Ҙ
} иҝҷдёӘеҮҪж•°жҳҜеӨҚеҲ¶ HAL_DMA_IRQHandler()еҮҪж•°пјҢ然еҗҺеўһеҠ NSSзҡ„ж“ҚдҪңгҖӮгҖҗжіЁж„ҸгҖ‘пјҡ
еңЁvoid DMA1_Channel2_3_IRQHandler(void)дёӯпјҢиҰҒе…Ҳи°ғHAL_DMA_IRQHandler(&hdma_spi1_rx); еҶҚи°ғз”ЁHAL_SPI1_TX_DMA_IRQHandler(&hdma_spi1_tx);еҮҪж•°пјҲи°ғжҚўдҪҚзҪ®ж—¶дјҡеҮәзҺ°ж•°жҚ®иҝҳжІЎдј иҫ“е®ҢпјҢNSSе°ұжӢүй«ҳзҡ„ж“ҚдҪңпјү
еҜ№дәҺSPI_DMAзҡ„йҖҡйҒ“дјҳе…Ҳзә§е°ҪйҮҸи®ҫзҪ®й«ҳзӮ№пјҢиҝҷж ·еҸҜд»ҘжӣҙеҘҪзҡ„дҝқиҜҒSPIдј иҫ“ж—¶й—ҙзҹӯ
е®һзҺ°ж•Ҳжһң
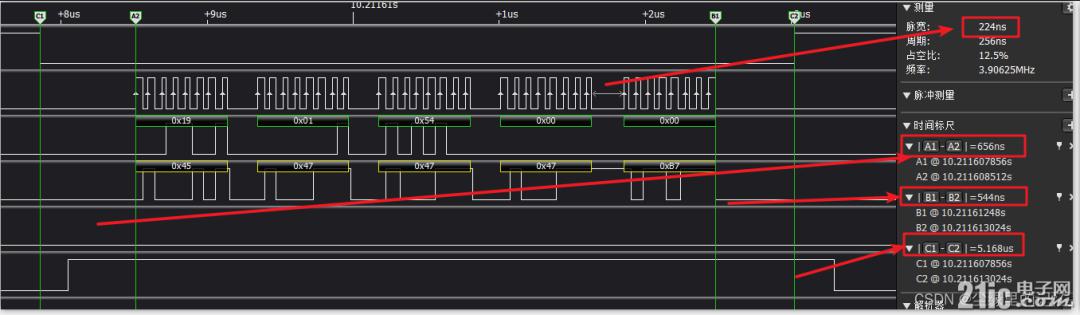
еҸ‘йҖҒ5дёӘеӯ—иҠӮеӨ§жҰӮйңҖиҰҒ5.16us,NSSдёҠдёӢжӢүж—¶й—ҙеңЁ600nsе·ҰеҸіпјҡ----------------ж—¶й—ҙпјҡ2021.12.02
дә”гҖҒе…ідәҺдёҠиҝ°е®һзҺ°зҡ„еҮәзҺ°зҡ„bug
1.иҜ»еҸ–еҮәзҺ°ж•°жҚ®й”ҷиҜҜй—®йўҳ
еңЁwhileдёӯжӯЈеёёеә”иҜҘжҳҜиҜ»еҮә0xA9B7дёәSX1280зҡ„IDпјҢдҪҶжҳҜе®һйҷ…иҜ»еҮәзҡ„еҚҙжҳҜ0xB7A9пјӣдё»иҰҒжҳҜSPIзҡ„жіўеҪўжІЎй—®йўҳпјҢд№ҹзЎ®е®һжҳҜе…ҲиҜ»еҲ°зҡ„0xA9пјҢеҶҚиҜ»зҡ„0xB7пјӣжңүдәӣеҘҮжҖӘпјҢдәҺжҳҜжғідјҡдёҚдјҡжҳҜDMAеӨӘеҝ«дәҶпјҢеҜјиҮҙеҚ•зүҮжңәиҜ»еҸ–ж•°жҚ®жңүй—®йўҳпјҹпјҹдәҺжҳҜжҲ‘еңЁи°ғз”ЁSPI_DMAзҡ„иҜ»еҶҷеҮҪж•°еҗҺеҠ дёҠдёӘзӯүеҫ…пјҢеҰӮдёӢ
/*
еҮҪж•°еҠҹиғҪпјҡиҜ»еӯ—иҠӮ
еҸӮж•°пјҡеҶҷе…Ҙзҡ„ж•°жҚ® иҜ»еҸ–зҡ„ж•°жҚ® еӨ§е°Ҹ
*/
void SpiInOut( uint8_t *txBuffer, uint8_t *rxBuffer, uint16_t size ){
SX1280_SPI_WR(txBuffer,rxBuffer,size);
while(__HAL_DMA_GET_COUNTER(&hdma_spi1_rx)!=0)
}жңҖз»ҲжөӢиҜ•еҸ‘зҺ°ж•°жҚ®жҳҜжӯЈзЎ®зҡ„пјҢиҜ»еҲ°зҡ„SX1280_ID=0xA9B7
2.дёӨеҢ…ж•°жҚ®д№Ӣй—ҙзҡ„й—ҙи·қеӨӘй•ҝ
еҲҡејҖе§Ӣд№ҹжңүиҜҙеҲ°пјҢжӯӨж¬Ўдё»иҰҒжҳҜдёәдәҶеҮҸзҹӯж—¶й—ҙпјҢиҖҢеңЁ дёҖгҖҒиҮӘиә«SPIзҡ„еӣҫйҮҢпјҢеӯ—иҠӮй—ҙи·қжҳҜжҜ”иҫғй•ҝзҡ„пјҢзҺ°еңЁдёӨдёӘеӯ—иҠӮй—ҙзҡ„ж—¶й—ҙжҳҜзј©зҹӯдәҶпјҢдҪҶжҳҜжҲ‘еҸ‘зҺ°еңЁдҪҝз”ЁSPI_DMAиҜ»еҶҷдёӨеҢ…ж•°жҚ®й—ҙзҡ„ж—¶й—ҙиҝҳжҳҜжҜ”иҫғй•ҝзҡ„пјҢ并且жҜ”йҮҮз”ЁBSP_SPIиҜ»еҶҷеҮҪж•°зҡ„ж—¶й—ҙиҝҳиҰҒй•ҝпјҢйӮЈдёҚжҳҜжІЎзј©зҹӯд»Җд№Ҳж—¶й—ҙеҗ—пјҹ
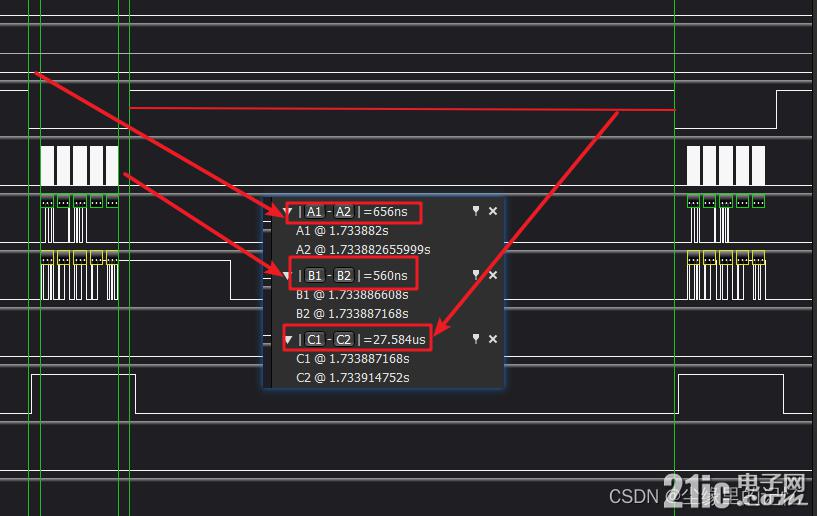
еҸҜд»ҘзңӢеҲ°дёӨеҢ…ж•°жҚ®й—ҙйҡ”27.5us,иҝҷж—¶й—ҙжңӘе…ҚжңүзӮ№й•ҝдәҶдәҺжҳҜжҲ‘е°ұејҖе§Ӣз ”з©¶пјҢеҰӮдҪ•зј©зҹӯдёӨеҢ…ж•°жҚ®й—ҙзҡ„ж—¶й—ҙгҖӮ
е…ӯгҖҒз ”з©¶еҰӮдҪ•зј©зҹӯж—¶й—ҙ
е…ідәҺиҝҷдёӘж—¶й—ҙпјҢжҲ‘зҢңжөӢеҫҲеҸҜиғҪжҳҜHALеј•иө·зҡ„пјҢеӣ дёәжҲ‘д»Јз ҒдёҠе°ұи·‘дәҶдёӘSPI_DMAзҡ„иҜ»еҶҷеҮҪж•°пјҢ并且HALзҡ„жү§иЎҢж•ҲзҺҮиҫғдҪҺпјҢжүҖд»ҘжҖҖз–‘жҳҜдёҚжҳҜHALжү§иЎҢзҡ„дёңиҘҝеӨӘеӨҡдәҶеҜјиҮҙзҡ„гҖӮ
1.еҜ№HAL_SPI_MY_TransmitReceive_DMA()еҮҪж•°еҲқжӯҘдјҳеҢ–
еӣ дёәHAL_SPI_MY_TransmitReceive_DMA()иҝҷдёӘеҮҪж•°жҲ‘жҳҜзӣҙжҺҘжҢӘз”Ёзҡ„HALзҡ„пјҢ然еҗҺеңЁејҖеҗҜDMAеүҚпјҢжӢүдҪҺдәҶдёӢNSSеј•и„ҡиҖҢе·ІпјҢжүҖд»ҘжҲ‘е°ұжғізқҖиғҪдёҚиғҪеҜ№жӯӨеҮҪж•°иҝӣиЎҢзІҫз®ҖгҖӮ
дәҺжҳҜжҲ‘еҜ№иҝҷдёӘеҮҪж•°иҝӣиЎҢеҲ йҷӨж“ҚдҪңпјҢеӣ дёәйҮҢйқўжңүи®ёеӨҡзҡ„дёҖдәӣеҲӨж–ӯпјҢжҲ‘ж №жҚ®жҲ‘SPI_DMAзҡ„й…ҚзҪ®пјҢе°ҶжҲ‘жІЎи®ҫзҪ®еҲ°д»Јз ҒйғҪз»ҷеҲ жҺүпјҢжңҖз»ҲеҸҳжҲҗдәҶиҝҷж ·гҖӮ
HAL_StatusTypeDef HAL_SPI_MY_TransmitReceive_DMA0(SPI_HandleTypeDef *hspi, uint8_t *pTxData, uint8_t *pRxData,uint16_t Size)
{
HAL_StatusTypeDef errorcode = HAL_OK;
/* Reset the threshold bit */
CLEAR_BIT(hspi->Instance->CR2, SPI_CR2_LDMATX | SPI_CR2_LDMARX);
/* Set fiforxthresold according the reception data length: 8bit */
SET_BIT(hspi->Instance->CR2, SPI_RXFIFO_THRESHOLD);
/* Enable the Rx DMA Stream/Channel */
// HAL_DMA_Start_IT(hspi->hdmarx, (uint32_t)&hspi->Instance->DR, (uint32_t)pRxData, Size);
{
/* Disable the peripheral */
hdma_spi1_rx.Instance->CCR &= ~DMA_CCR_EN;
/* Configure the source, destination address and the data length */
//DMA_SetConfig(hdma_spi1_rx, (uint32_t)&hspi->Instance->DR, (uint32_t)pRxData, Size);
{
/* Clear all flags */
hdma_spi1_rx.DmaBaseAddress->IFCR = (DMA_FLAG_GL1 << hdma_spi1_rx.ChannelIndex);
/* Configure DMA Channel data length */
hdma_spi1_rx.Instance->CNDTR = Size;
/* Peripheral to Memory */
{
/* Configure DMA Channel source address */
hdma_spi1_rx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
/* Configure DMA Channel destination address */
hdma_spi1_rx.Instance->CMAR = (uint32_t)pRxData;
}
}
/* Enable the transfer complete, & transfer error interrupts */
/* Half transfer interrupt is optional: enable it only if associated callback is available */
hdma_spi1_rx.Instance->CCR |= (DMA_IT_TC | DMA_IT_HT | DMA_IT_TE);
/* Enable the Peripheral */
hdma_spi1_rx.Instance->CCR |= DMA_CCR_EN;
}
/* Enable Rx DMA Request */
SET_BIT(hspi->Instance->CR2, SPI_CR2_RXDMAEN);
/* Enable the Tx DMA Stream/Channel */
// HAL_DMA_Start_IT(hspi->hdmatx, (uint32_t)pTxData, (uint32_t)&hspi->Instance->DR,Size);
{
/* Disable the peripheral */
hdma_spi1_tx.Instance->CCR &= ~DMA_CCR_EN;
/* Configure the source, destination address and the data length */
// DMA_SetConfig(hdma_spi1_rx, (uint32_t)&hspi->Instance->DR, (uint32_t)pRxData, Size);
{
/* Clear all flags */
hdma_spi1_tx.DmaBaseAddress->IFCR = (DMA_FLAG_GL1 << hdma_spi1_rx.ChannelIndex);
/* Configure DMA Channel data length */
hdma_spi1_tx.Instance->CNDTR = Size;
/* Memory to Peripheral */
{
/* Configure DMA Channel destination address */
hdma_spi1_tx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
/* Configure DMA Channel source address */
hdma_spi1_tx.Instance->CMAR = (uint32_t)pTxData;
}
}
/* Enable the transfer complete, & transfer error interrupts */
/* Half transfer interrupt is optional: enable it only if associated callback is available */
hdma_spi1_tx.Instance->CCR |= (DMA_IT_TC | DMA_IT_HT | DMA_IT_TE);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_RESET);
/* Enable the Peripheral */
hdma_spi1_tx.Instance->CCR |= DMA_CCR_EN;
}
/* Check if the SPI is already enabled */
if ((hspi->Instance->CR1 & SPI_CR1_SPE) != SPI_CR1_SPE)
{
/* Enable SPI peripheral */
__HAL_SPI_ENABLE(hspi);
}
/* Enable the SPI Error Interrupt Bit */
__HAL_SPI_ENABLE_IT(hspi, (SPI_IT_ERR));
/* Enable Tx DMA Request */
SET_BIT(hspi->Instance->CR2, SPI_CR2_TXDMAEN);
return errorcode;
}然еҗҺиҝӣиЎҢжөӢиҜ•пјҢжөӢиҜ•з»“жһңеҰӮдёӢпјҢеҸҜд»ҘзңӢеҲ°иҷҪ然дёӨеҢ…ж•°жҚ®й—ҙзҡ„ж—¶й—ҙеҮҸе°‘дәҶпјҢдҪҶиҝҳжҳҜжңүдёӘ16.48us,иҝҷдёӘж—¶й—ҙеҜ№дәҺжҲ‘иҝҳжҳҜеӨӘй•ҝдәҶпјҢеӣ дёәжҲ‘йҮҮз”ЁBSP_SPIиҜ»еҶҷеҮҪж•°ж—¶пјҢдёӨеҢ…ж•°жҚ®й—ҙд№ҹе°ұ2-3usе·ҰеҸіпјҢиҝҷдёӘж—¶й—ҙиҝҳжҳҜжҳҺжҳҫеҒҸй•ҝгҖӮ
2.иҝӣдёҖжӯҘдјҳеҢ–
еҰӮдҪ•еңЁиҝӣдёҖжӯҘпјҢзј©зҹӯж—¶й—ҙпјҢеҶҚеҜ№жӯӨеҮҪж•°иҝӣиЎҢдјҳеҢ–пјҹе°Ҷе…¶ж”№жҲҗзӣҙжҺҘж“ҚдҪңеҜ„еӯҳеҷЁпјҹ
еңЁжӯӨйңҖзү№еҲ«ж„ҹи°ў 21icи®әеқӣзҡ„зүҲдё» @е‘җе’ҜеҜҶеҜҶеңЁжҲ‘и°ғиҜ•иҝҮзЁӢдёӯз»ҷдәҲжҲ‘зү№еҲ«еӨҡзҡ„её®еҠ©гҖӮ
еңЁд»–зҡ„её®еҠ©дёӢпјҢе°ҶдёҠиҝ°зҡ„иҜ»еҶҷеҮҪж•°пјҢеҶҚиҝӣдёҖжӯҘдјҳеҢ–гҖӮ
HAL_StatusTypeDef HAL_SPI_MY_TransmitReceive_DMA0(SPI_HandleTypeDef *hspi, uint8_t *pTxData, uint8_t *pRxData,uint16_t Size)
{
HAL_StatusTypeDef errorcode = HAL_OK;
hspi->Instance->CR2 |= SPI_CR2_TXDMAEN;
hspi->Instance->CR2 |= SPI_CR2_RXDMAEN;
hdma_spi1_tx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_tx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_tx.Instance->CMAR = (uint32_t)pTxData;
hdma_spi1_tx.Instance->CNDTR = Size;
hdma_spi1_tx.Instance->CCR |= (DMA_IT_TC | DMA_IT_HT | DMA_IT_TE);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_RESET);
hdma_spi1_tx.Instance->CCR |= DMA_CCR_EN;
hdma_spi1_rx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_rx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_rx.Instance->CMAR = (uint32_t)pRxData;
hdma_spi1_rx.Instance->CNDTR = Size;
hdma_spi1_rx.Instance->CCR |= (DMA_IT_TC | DMA_IT_HT | DMA_IT_TE);
hdma_spi1_rx.Instance->CCR |= DMA_CCR_EN;
/* Enable SPI peripheral */
// __HAL_SPI_ENABLE(hspi);
hspi->Instance->CR1 |= SPI_CR1_SPE;
return errorcode;
}зҺ°еңЁе·Із»Ҹе…Ёж”№жҲҗеҜ„еӯҳеҷЁж“ҚдҪңдәҶпјҢиҝӣиЎҢжөӢиҜ•
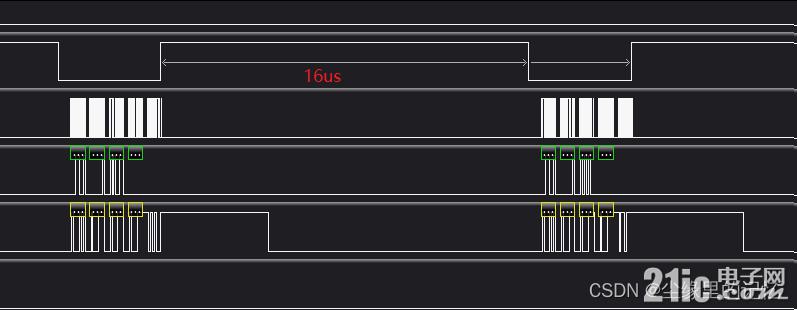
з»“жһңиҝҳжңү16usзҡ„ж—¶й—ҙпјҹпјҹпјҹпјҹе•Ҙжғ…еҶөпјҢиҜ»еҶҷеҮҪж•°е·Із»ҸеҲ еҮҸеҲ°еҜ„еӯҳдәҶпјҢиҝҳиҝҷд№ҲеӨҡж—¶й—ҙпјҹпјҹпјҹ
3.еҜ№дёӯж–ӯиҝӣиЎҢдјҳеҢ–
иҝҷж—¶еҗ¬еӨ§е“ҘиҜҙпјҢд»–з”Ёзҡ„SPI+DMAдёҚеёҰдёӯж–ӯзҡ„пјҢиҝҷж—¶жҲ‘жүҚзӘҒ然еҸҚеә”иҝҮжқҘпјҢеңЁдёӯж–ӯйҮҢд№ҹжҳҜз”Ёзҡ„HALи°ғз”Ёзҡ„е‘ҖпјҢиҝҷйҮҢд№ҹиҰҒиҝӣиЎҢдјҳеҢ–пјҒпјҒпјҒ
/*whileдёӯж“ҚдҪңпјҢеҸӘжү§иЎҢиҜ»еҶҷеҮҪж•°*/
uint8_t txbuff[5]={0x19,0x01,0x53,0x00,0x00};
uint8_t rxbuff[5];
/* Infinite loop */
/* USER CODE BEGIN WHILE */
while (1)
{
HAL_SPI_MY_TransmitReceive_DMA0(&hspi1, txbuff,rxbuff,5);
HAL_SPI_MY_TransmitReceive_DMA0(&hspi1, txbuff,rxbuff,5);
// SX1280_ID = Radio.GetFirmwareVersion();//иҺ·еҸ–иҠҜзүҮдҝЎжҒҜ 0xA9B7 еҸҜз”ЁдәҺжөӢиҜ•SPIзҡ„иҜ»еҶҷжғ…еҶө
HAL_GPIO_TogglePin(LED_Red_GPIO_Port,LED_Red_Pin);
HAL_Delay(50);
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}/*SPI_DMAзҡ„иҜ»еҶҷеҮҪж•°*/
HAL_StatusTypeDef HAL_SPI_MY_TransmitReceive_DMA0(SPI_HandleTypeDef *hspi, uint8_t *pTxData, uint8_t *pRxData,uint16_t Size)
{
hspi->Instance->CR2 |= SPI_CR2_TXDMAEN;
hspi->Instance->CR2 |= SPI_CR2_RXDMAEN;
hdma_spi1_tx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_tx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_tx.Instance->CMAR = (uint32_t)pTxData;
hdma_spi1_tx.Instance->CNDTR = Size;
//hdma_spi1_tx.Instance->CCR |= (DMA_IT_TC | DMA_IT_HT | DMA_IT_TE);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_RESET);
hdma_spi1_tx.Instance->CCR |= DMA_CCR_EN;
hdma_spi1_rx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_rx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_rx.Instance->CMAR = (uint32_t)pRxData;
hdma_spi1_rx.Instance->CNDTR = Size;
hdma_spi1_rx.Instance->CCR |= (DMA_IT_TC);//| DMA_IT_HT | DMA_IT_TE);
hdma_spi1_rx.Instance->CCR |= DMA_CCR_EN;
hspi->Instance->CR1 |= SPI_CR1_SPE;
}/*DMAдёӯж–ӯ*/
void DMA1_Channel2_3_IRQHandler(void)
{
/* USER CODE BEGIN DMA1_Channel2_3_IRQn 0 */
/* USER CODE END DMA1_Channel2_3_IRQn 0 */
// HAL_DMA_IRQHandler(&hdma_spi1_rx);
// HAL_DMA_IRQHandler(&hdma_spi1_tx);
/* USER CODE BEGIN DMA1_Channel2_3_IRQn 1 */
if(__HAL_DMA_GET_IT_SOURCE(&hdma_spi1_rx, DMA_IT_TC)){
hdma_spi1_rx.Instance->CCR &= ~(DMA_IT_TC );
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_SET);
}
/* USER CODE END DMA1_Channel2_3_IRQn 1 */
}зҺ°еңЁеҜ№дёҠиҝ°иҝӣиЎҢдјҳеҢ–дәҶпјҢ然еҗҺиҝӣиЎҢжөӢиҜ•
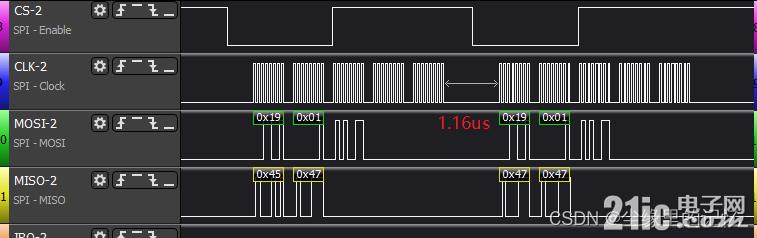
еҸҜд»ҘзңӢеҲ°дёӨеҢ…ж•°жҚ®й—ҙзҡ„й—ҙи·қжҳҜ1.16usдәҶпјҢиҷҪ然иҜҙзҺ°еңЁж•°жҚ®й”ҷиҜҜпјҢдҪҶжҳҜиҮіе°‘иҜҙжҳҺпјҢдҝ®ж”№дёӯж–ӯйҮҢзҡ„ж“ҚдҪңжҳҜжІЎй—®йўҳзҡ„гҖӮ
4.жңҖз»ҲдјҳеҢ–з»“жһң
зҺ°еңЁеҶҚиҝӣдёҖжӯҘжөӢиҜ•пјҢеҺ»жҺүдёӯж–ӯпјҲжҲ‘жң¬жғіжҳҜж•°жҚ®дј иҫ“е®ҢеҗҺпјҢз«ӢеҲ»жӢүй«ҳNSSеј•и„ҡпјҢдҪҶжҳҜзҺ°еңЁзңӢжқҘжҳҜжҲ‘еҜ№TCдёӯж–ӯжңүиҜҜи§ЈдәҶпјҢеӣ дёәдёҠеӣҫзҡ„жөӢиҜ•зҺ°иұЎиҜҙжҳҺпјҢи§ҰеҸ‘дәҶTCдёӯж–ӯпјҢдҪҶжҳҜж•°жҚ®е№¶жІЎжңүдј иҫ“е®Ңпјү

зҺ°еңЁе…ій—ӯдёӯж–ӯпјҢзӯүеҫ…дј иҫ“е®ҢеҗҺеңЁжӢүй«ҳNSSпјҢе°ҶиҜ»еҶҷеҮҪж•°иҝӣиЎҢеҰӮдёӢдҝ®ж”№
void HAL_SPI_MY_TransmitReceive_DMA0(SPI_HandleTypeDef *hspi, uint8_t *pTxData, uint8_t *pRxData,uint16_t Size)
{
hspi->Instance->CR2 |= SPI_CR2_TXDMAEN;
hspi->Instance->CR2 |= SPI_CR2_RXDMAEN;
hdma_spi1_tx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_tx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_tx.Instance->CMAR = (uint32_t)pTxData;
hdma_spi1_tx.Instance->CNDTR = Size;
//hdma_spi1_tx.Instance->CCR |= (DMA_IT_TC | DMA_IT_HT | DMA_IT_TE);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_RESET);
hdma_spi1_tx.Instance->CCR |= DMA_CCR_EN;
hdma_spi1_rx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_rx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_rx.Instance->CMAR = (uint32_t)pRxData;
hdma_spi1_rx.Instance->CNDTR = Size;
// hdma_spi1_rx.Instance->CCR |= (DMA_IT_TC);//| DMA_IT_HT | DMA_IT_TE);
hdma_spi1_rx.Instance->CCR |= DMA_CCR_EN;
hspi->Instance->CR1 |= SPI_CR1_SPE;
while((hspi->Instance->SR & SPI_SR_RXNE)!=RESET);
while((hspi->Instance->SR & SPI_SR_BSY)!=RESET);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_SET);
}еҸӘеҜ№SPI_DMAиҜ»еҶҷеҮҪж•°иҝӣиЎҢдҝ®ж”№пјҢеңЁwhileдёӯиҝҳжҳҜеҸ‘йҖҒйӮЈдәӣжҢҮд»ӨпјҢеңЁиҜ»еҶҷеҮҪж•°дёӯдёҚејҖеҗҜдёӯж–ӯпјҢеўһеҠ зӯүеҫ…
while((hspi->Instance->SR & SPI_SR_RXNE)!=RESET);while((hspi->Instance->SR & SPI_SR_BSY)!=RESET);HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_SET);
жөӢиҜ•з»“жһңпјҡ
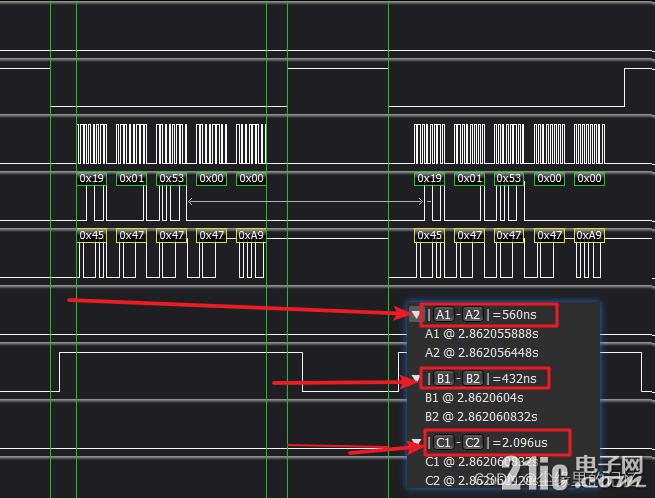
дёҠеӣҫдёӯNSSжӢүдҪҺеҲ°ејҖе§Ӣдј иҫ“ж•°жҚ®560ns,ж•°жҚ®дј иҫ“е®ҢжҲҗеҲ°NSSжӢүй«ҳ432ns,дёӨеҢ…ж•°жҚ®й—ҙйҡ”жҳҜ2.09us
дёғгҖҒжңҖз»ҲжөӢиҜ•ж•°жҚ®еҸҠй…ҚзҪ®
1.жөӢиҜ•ж•°жҚ®
еңЁиҝҷеҸҜд»Ҙе°ҶжҲ‘第 дә”.1дёӯж•°жҚ®й”ҷиҜҜзҡ„дҝ®ж”№еҺ»жҺү
/*
еҮҪж•°еҠҹиғҪпјҡиҜ»еӯ—иҠӮ
еҸӮж•°пјҡеҶҷе…Ҙзҡ„ж•°жҚ® иҜ»еҸ–зҡ„ж•°жҚ® еӨ§е°Ҹ
*/
void SpiInOut( uint8_t *txBuffer, uint8_t *rxBuffer, uint16_t size ){
SX1280_SPI_WR(txBuffer,rxBuffer,size);
//while(__HAL_DMA_GET_COUNTER(&hdma_spi1_rx)!=0)
}еҗҢж—¶й…ҚзҪ®жҲҗдёҠиҝ°иҜ»еҸ–зҡ„ж•°жҚ®жӯЈзЎ®зҡ„
while (1)
{
HAL_SPI_MY_TransmitReceive_DMA0(&hspi1, txbuff,rxbuff,5);
HAL_SPI_MY_TransmitReceive_DMA0(&hspi1, txbuff,rxbuff,5);
/*иҝҷйҮҢеҸ‘йҖҒдәҶдёӨеҢ…ж•°жҚ®пјҢжӯЈеёёиҝ”еӣһ 0xA9B7*/
SX1280_ID = Radio.GetFirmwareVersion();//иҺ·еҸ–иҠҜзүҮдҝЎжҒҜ 0xA9B7 еҸҜз”ЁдәҺжөӢиҜ•SPIзҡ„иҜ»еҶҷжғ…еҶө
HAL_GPIO_TogglePin(LED_Red_GPIO_Port,LED_Red_Pin);
HAL_Delay(50);
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
}е…ідәҺдёҠиҝ°whileдёӯзҡ„жөӢиҜ•зҺ°иұЎеҰӮдёӢ
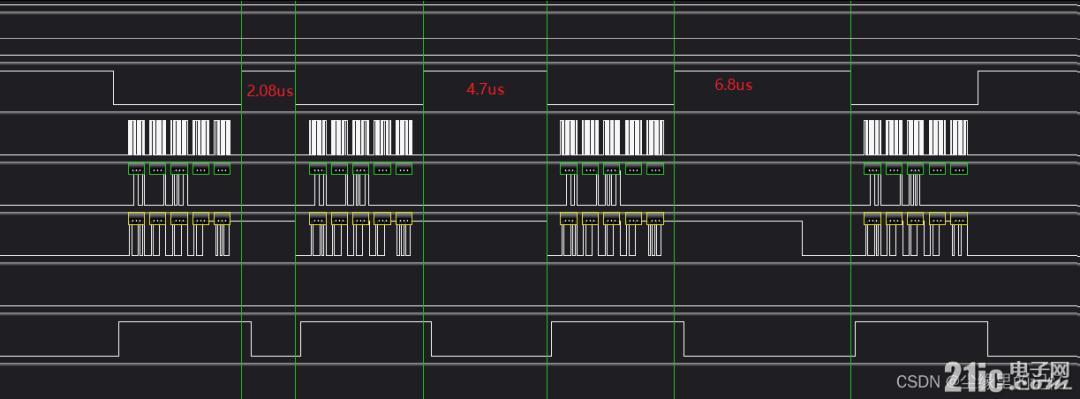
еүҚдёӨеҢ…ж•°жҚ®й—ҙи·қжҳҜ2.08us,еҗҺйқўдёӨеҢ…ж•°жҚ®й—ҙи·қжҳҜ6.8us,иҝҷжҳҜеӣ дёәиҜ»еҸ–SX1280_IDжҳҜйҖҡиҝҮи°ғз”ЁSX1280иҮӘиә«зҡ„еә“пјҢ然еҗҺеҶҚи°ғз”ЁжҲ‘е°ҒиЈ…зҡ„йӮЈдёӘSPI_DMAиҜ»еҶҷеҮҪж•°гҖӮ
2.й…ҚзҪ®
/*mainеҮҪж•°*/
int main(void){
HAL_Init();
SystemClock_Config();
MX_GPIO_Init();
MX_DMA_Init();
MX_SPI1_Init();
Radio.Init( &Callbacks );//еҲқе§ӢеҢ–еӣһи°ғеҮҪж•°
Radio.SetRegulatorMode( USE_DCDC ); // д№ҹеҸҜд»Ҙи®ҫзҪ®дёәLDOжЁЎејҸдҪҶж¶ҲиҖ—жӣҙеӨҡеҠҹзҺҮ USE_DCDC USE_LDO
uint8_t txbuff[5]={0x19,0x01,0x53,0x00,0x00};
uint8_t rxbuff[5];
while (1)
{
HAL_SPI_MY_TransmitReceive_DMA(&hspi1, txbuff,rxbuff,5);
HAL_SPI_MY_TransmitReceive_DMA(&hspi1, txbuff,rxbuff,5);
SX1280_ID = Radio.GetFirmwareVersion();//иҺ·еҸ–иҠҜзүҮдҝЎжҒҜ 0xA9B7 еҸҜз”ЁдәҺжөӢиҜ•SPIзҡ„иҜ»еҶҷжғ…еҶө
HAL_GPIO_TogglePin(LED_Red_GPIO_Port,LED_Red_Pin);
HAL_Delay(50);
}
}
/*DMAй…ҚзҪ®*/
void MX_DMA_Init(void)
{
__HAL_RCC_DMA1_CLK_ENABLE();//ејҖеҗҜDMAж—¶й’ҹеҚіеҸҜ
/* дёҚйңҖиҰҒй…ҚзҪ®DMAзҡ„дјҳе…Ҳзә§пјҢеӣ дёәжІЎз”ЁеҲ°DMAдёӯж–ӯ */
// HAL_NVIC_SetPriority(DMA1_Channel2_3_IRQn, 0, 0);
// HAL_NVIC_EnableIRQ(DMA1_Channel2_3_IRQn);
}
/*SPIй…ҚзҪ®*/
void MX_SPI1_Init(void)
{
hspi1.Instance = SPI1;
hspi1.Init.Mode = SPI_MODE_MASTER;
hspi1.Init.Direction = SPI_DIRECTION_2LINES;
hspi1.Init.DataSize = SPI_DATASIZE_8BIT;
hspi1.Init.CLKPolarity = SPI_POLARITY_LOW;
hspi1.Init.CLKPhase = SPI_PHASE_1EDGE;
hspi1.Init.NSS = SPI_NSS_SOFT;
hspi1.Init.BaudRatePrescaler = SPI_BAUDRATEPRESCALER_4;
hspi1.Init.FirstBit = SPI_FIRSTBIT_MSB;
hspi1.Init.TIMode = SPI_TIMODE_DISABLE;
hspi1.Init.CRCCalculation = SPI_CRCCALCULATION_DISABLE;
hspi1.Init.CRCPolynomial = 7;
hspi1.Init.CRCLength = SPI_CRC_LENGTH_DATASIZE;
hspi1.Init.NSSPMode = SPI_NSS_PULSE_ENABLE;
if (HAL_SPI_Init(&hspi1) != HAL_OK)
{
Error_Handler();
}
}
void HAL_SPI_MspInit(SPI_HandleTypeDef* spiHandle)
{
GPIO_InitTypeDef GPIO_InitStruct = {0};
if(spiHandle->Instance==SPI1)
{
/* SPI1 clock enable */
__HAL_RCC_SPI1_CLK_ENABLE();
__HAL_RCC_GPIOA_CLK_ENABLE();
__HAL_RCC_GPIOB_CLK_ENABLE();
/**SPI1 GPIO Configuration
PB3 ------> SPI1_SCK
PB4 ------> SPI1_MISO
PB5 ------> SPI1_MOSI
*/
GPIO_InitStruct.Pin = GPIO_PIN_3|GPIO_PIN_4|GPIO_PIN_5;
GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;
GPIO_InitStruct.Pull = GPIO_NOPULL;
GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_HIGH;
GPIO_InitStruct.Alternate = GPIO_AF0_SPI1;
HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);
/* SPI1 DMA Init */
/* SPI1_TX Init */
hdma_spi1_tx.Instance = DMA1_Channel3;
hdma_spi1_tx.Init.Direction = DMA_MEMORY_TO_PERIPH;
hdma_spi1_tx.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_spi1_tx.Init.MemInc = DMA_MINC_ENABLE;
hdma_spi1_tx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_spi1_tx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
hdma_spi1_tx.Init.Mode = DMA_NORMAL;
hdma_spi1_tx.Init.Priority = DMA_PRIORITY_MEDIUM;
if (HAL_DMA_Init(&hdma_spi1_tx) != HAL_OK)
{
Error_Handler();
}
__HAL_LINKDMA(spiHandle,hdmatx,hdma_spi1_tx);
/* SPI1_RX Init */
hdma_spi1_rx.Instance = DMA1_Channel2;
hdma_spi1_rx.Init.Direction = DMA_PERIPH_TO_MEMORY;
hdma_spi1_rx.Init.PeriphInc = DMA_PINC_DISABLE;
hdma_spi1_rx.Init.MemInc = DMA_MINC_ENABLE;
hdma_spi1_rx.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_spi1_rx.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
hdma_spi1_rx.Init.Mode = DMA_NORMAL;
hdma_spi1_rx.Init.Priority = DMA_PRIORITY_MEDIUM;
if (HAL_DMA_Init(&hdma_spi1_rx) != HAL_OK)
{
Error_Handler();
}
__HAL_LINKDMA(spiHandle,hdmarx,hdma_spi1_rx);
/* жңӘз”ЁеҲ°SPIдёӯж–ӯпјҢд№ҹеҸҜдёҚз”Ёй…ҚзҪ® */
// HAL_NVIC_SetPriority(SPI1_IRQn, 0, 0);
// HAL_NVIC_EnableIRQ(SPI1_IRQn);
}
}
/*SPI_DMAиҜ»еҶҷеҮҪж•°*/
void HAL_SPI_MY_TransmitReceive_DMA(SPI_HandleTypeDef *hspi, uint8_t *pTxData, uint8_t *pRxData,uint16_t Size)
{
hspi->Instance->CR2 |= SPI_CR2_TXDMAEN;
hspi->Instance->CR2 |= SPI_CR2_RXDMAEN;
hdma_spi1_tx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_tx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_tx.Instance->CMAR = (uint32_t)pTxData;
hdma_spi1_tx.Instance->CNDTR = Size;
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_RESET);
hdma_spi1_tx.Instance->CCR |= DMA_CCR_EN;
hdma_spi1_rx.Instance->CCR &= ~DMA_CCR_EN;
hdma_spi1_rx.Instance->CPAR = (uint32_t)&hspi->Instance->DR;
hdma_spi1_rx.Instance->CMAR = (uint32_t)pRxData;
hdma_spi1_rx.Instance->CNDTR = Size;
hdma_spi1_rx.Instance->CCR |= DMA_CCR_EN;
hspi->Instance->CR1 |= SPI_CR1_SPE;
while((hspi->Instance->SR & SPI_SR_RXNE)!=RESET);
while((hspi->Instance->SR & SPI_SR_BSY)!=RESET);
HAL_GPIO_WritePin(GPIOA, GPIO_PIN_15, GPIO_PIN_SET);
}е…ідәҺе…·дҪ“д»Јз ҒпјҢзЁҚеҗҺж”ҫеҲ°githubдёҠ(йҷ„件дёҠдј дёҚдәҶ)
е…ідәҺеҰӮдҪ•еҮҸе°‘ж—¶й—ҙпјҢеӨ§е®¶жңүжӣҙеҘҪзҡ„ж–№жі•пјҢж¬ўиҝҺи®Ёи®әиҒ”зі»пјҢи°ўи°ўпјҒ
е…ідәҺжөӢиҜ•е·ҘзЁӢпјҢgithubй“ҫжҺҘпјҡhttps://github.com/Gu-Yue-Hu/SPI_DMA_HAL.git
жң¬ж–Үзі»21icи®әеқӣзҪ‘еҸӢchenyuanjiyiеҺҹеҲӣпјҢжҺҲжқғиҪ¬иҪҪпјҒ
-End-
гҖҢжңүз”Ёе°ұжү©ж•ЈгҖҚ
зӮ№еҮ»дёӢж–№вҖң硬件攻еҹҺзӢ®вҖқе…іжіЁпјҢйҖүжӢ©вҖңзҪ®йЎ¶/жҳҹж Үе…¬дј—еҸ·вҖқ
з”өеӯҗжҠҖжңҜе№Іиҙ§пјҢ第дёҖж—¶й—ҙйҖҒиҫҫ
????

